
▶ データの概要を把握したい場合は、以下の投稿も参考にしてください。


はじめに
今回は行と列の入れ替えを扱います。行列を扱っていると、行列を回転させて行と列を入れ替えるケースや機械学習では行列の次元を変換するケースもあります。ただ、そういったケースではなくても、行と列を入れ替えるとみやすい、ということもあります。今回はpandasのデータフレームで行と列を入れ替える方法をご紹介します。
サンプルデータ
今回は長野県岡谷市の住民基本台帳人口のデータを使ってみましょう。岡谷市を選択した意味は特にありません。データはここから取得しました。
取得したデータを取り込んでみましょう。今回は1ファイルのみなのであまり意味はありませんが、前回の投稿で扱った、os.path.join()を使って取り込んでみましょう。
# ライブラリのインポート import pandas as pd import os # ディレクトリの設定 INPUT_DIR='C:\python\data/' file='population.csv' # データの読み込み data=pd.read_csv(os.path.join(INPUT_DIR,file)) data.head(3)
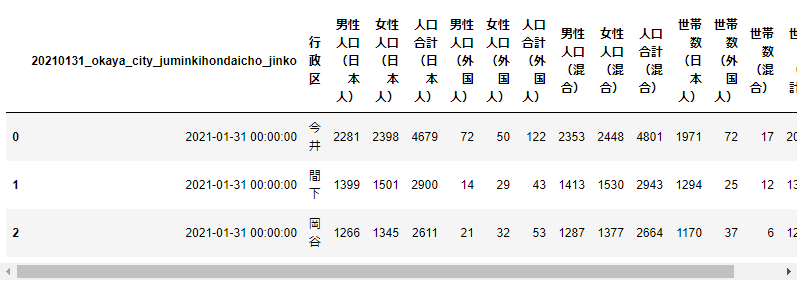
利用シーン
利用シーン
データを無事読み込むことができましたが、少し見にくくないでしょうか?列項目の多いデータフレームではすべての列が表示されない(表示上は省略されて・・・の表示になる)ことがあります。また、先ほどの例のように表示はされるが、横スクロールバーが表示されてスクロールをしなければならない場合もあります。
このようなときに、行と列を入れ替えてみるだけで、とてもみやすくなります。また、データフレームの基礎統計量を算出するdescribe()の実行結果も、行と列を入れ替えることで、列項目の統計量を比較しやすくなります。
行と列の入れ替え
では、先ほどのデータフレームの行と列をさっそく入れ替えてみましょう。これは非常に簡単です。データフレームのTアトリビュートにアクセスするだけです。次のようにします。
data.head(3).T
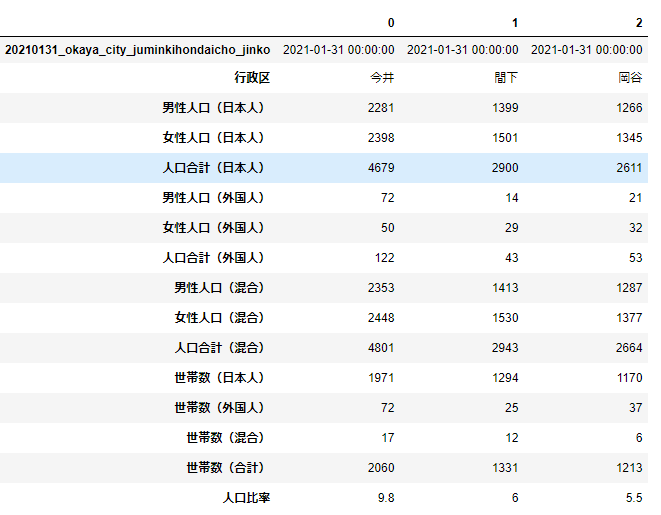
いかがですか?格段にみやすくなったのではないでしょうか?列数がさらに多いときなどは、特に重宝します。続けて、利用シーンで記載した基本統計量についても確認してみましょう。
# 普通に基礎統計量を表示 data.describe()
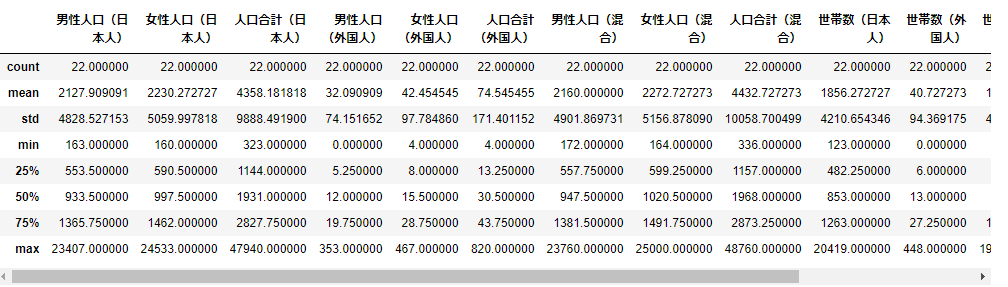
やはり横スクロールバーが出てきてしまって、見にくいですね。これも行と列を入れ替えてみましょう。
# 基礎統計量:行と列を入れ替えて表示 data.describe().T
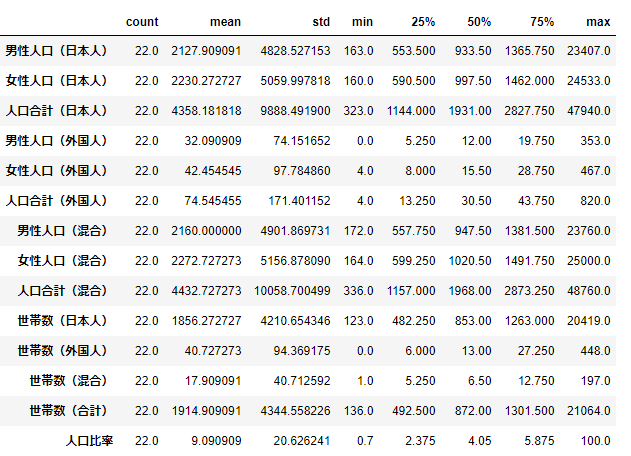
こちらもみやすくなりましたね。
まとめ
いかがでしたか?ほんのちょっとしたことですが、これだけで作業効率があがることもあります。特に基礎統計量の比較の際などはみやすいですよね。ちょっとみにくいなぁ、と感じた時に思い出してみてください。
▶ クロス集計をするなら以下の記事を参考にしてください。

コメント