
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ Pandasの基本を解説しています。Series/DataFrameの作り方は以下をご覧ください。


はじめに
今回はデータフレームのイテレーションについて基本から解説します。イテレーションとは簡単にいうと繰り返しのことです。これまでにもforループやWhileループなどの繰り返し処理を見てきました。今回は、データフレームの場合の繰り返し処理について扱っていきます。
データフレームの繰り返し処理(イテレーション)
データフレームを扱っていると、各列や各行に繰り返し処理を加えたくなることがありますね。今回はこの処理の仕方を整理していきます。まずはサンプルのデータフレームを用意しましょう。
# ライブラリのインポート
import numpy as np
import pandas as pd
# サンプルのデータフレーム作成
np.random.seed(0)
zoo = ['上野動物園','旭山動物園','ズーラシア','宇都宮動物園','八景島シーパラダイス','江ノ島水族館']
number_of_salesperson = np.random.randint(1,5,size=6)
sales = np.random.randint(200000,1000000,size=6)
cost = np.random.randint(80000,150000,size=6)
df = pd.DataFrame({
'動物園':zoo,
'営業の数':number_of_salesperson,
'売上':sales,
'費用':cost})
df = df.set_index('動物園')
df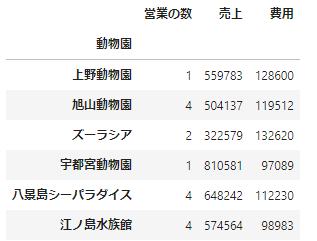
apply()を使う
では早速やっていきます。各行や各列に関数を適用したい場合は、apply()を使います。まずは書式を確認しておきましょう。
axisはもうお馴染みですね。axis=0で列方向、axis=1で行方向となります。試してみましょう。
# データフレームから各列を取り出して関数を適用
df.apply(lambda x:x.max(),axis=0)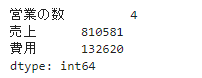
列ごとに最大値を求めました。axis=0とするとデータフレームから各列をSeriesとして取り出して関数を適用しています。次にaxis=1の例を見てみましょう。
# データフレームから各行を取り出して関数を適用
df['ランク'] = df.apply(lambda x:'A' if x['売上']-x['費用']>500000 else 'B',axis=1)
df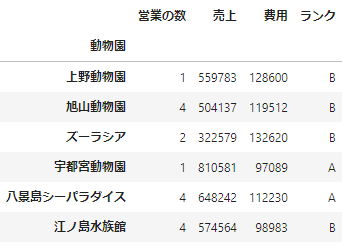
axis=1とするとデータフレームから各行をSeriesとして取り出して関数を適用しています。ここでは「売上」-「費用」が500000より大きい場合はランクA、小さい場合はランクBと判定する関数を適用しています。
各行を取り出した後、複数の列を用いて演算する場合は、上記のようにdf.apply()としますが、一つの列のみを用いて演算する場合は、次のようにすることもできます。
例えば売上の値だけを使って判定する場合は次のようにできます。
# Seriesに関数を適用
df['売上ランク'] = df['売上'].apply(lambda x:'A' if x>500000 else 'B')
df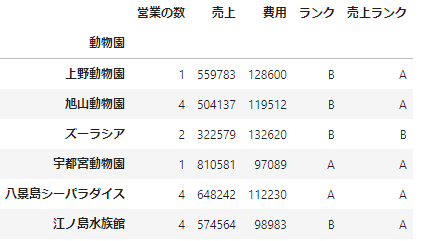
iterrows()を使う
データフレームの行を取り出して繰り返し処理することもできます。iterrows()を使います。わかりやすい名前ですね。apply()ではあらかじめ定義された関数、あるいはlambda関数を適用させますが、iterrows()では取り出した行に対して繰り返し処理を記述していくことができます。
iterrows()メソッドを使うと、インデックス名(行名)とその行のデータ(pandas.Series型)のタプル(index, Series)を1行ずつ取得できます。やってみましょう。
# iterrows()でforループ
for idx,row in df.iterrows():
print('{}の売上は{}です'.format(idx,row['売上']))
(index, Series)がタプルで取り出されるので、idx, rowで受け取っています。idxにはインデックス、rowには行のデータがSeriesで入っています。行のデータのうち、「売上」だけを使うのでrow[‘売上’]としています。
まとめ
今回はデータフレームの繰り返し処理を扱いました。各行・各列に関数を適用したい場合にはapply()を使います。forループの処理をおこないたいときは、iterrows()メソッドでインデックスと行を取り出すことで可能です。行ではなく列を取り出すiteritems()というメソッドもありますが、個人的にはあまり使う場面もなかったので割愛しました。今後、必要になった時に調べて使えればよいかと思います。
コメント