
▶ 不均衡データの処理については以下の記事を参考にして下さい。

はじめに
今回はサンプリングについて扱います。実データを扱っていると、データが不均衡であることがたびたびあります。たとえば、メルマガ会員などはでは、大多数の会員が継続(yes)して、ほんの一部の会員が配信停止処理(no)をする、といった場合です。偏りのあるデータでモデルを作ると、一方を(この場合は会員を継続する)予想するモデルになりがちです。よってyesとnoのデータ件数が均衡になるように加工する必要があります。
やり方は2つあります。多数のデータ件数を少数のデータ件数と同じにする、つまり、多数のデータから一部のデータを抜き取る方法です。これを「アンダーサンプリング」といいます。
実際には、予測したい方のデータが少なすぎることもあります。このような場合は、多数のデータを少数のデータに合わせると、モデルを作成するのに必要なデータが不足します。このような場合は、少数のデータを複製してデータ件数を増やして、多数データの件数と合わせる方法をとります。これを「オーバーサンプリング」といいます。
このようにサンプリングしたシーンというのはいろいろありますが、今回は単純に手元にあるデータの一部を抜き出す方法についてみていきましょう。
サンプルデータの準備
どうぶつたちのテスト結果のデータを作りましょう。(サンプリングの方法がわかればよいので、特に不均衡データにはしていません)
# ライブラリのインポート
import pandas as pd
import numpy as np
import random
pd.options.display.precision=1
# サンプルデータの作成
animals=['らくだ','らいおん','らくだ','しまうま']
df=pd.DataFrame({'なまえ':random.choices(animals,k=10000),
'とくてん':np.random.randint(55,86,10000)})
df.head()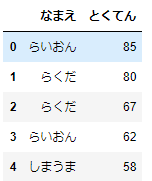
このデータを使って、サンプリングをしてみることにしましょう。
データのサンプリング
単純無作為抽出
まずは単純に無作為に抽出する方法です。たとえばデータ全体の1%を無作為に取り出すことにしましょう。次のようにsample()メソッドをつかうことができます。
df_01=df.sample(frac=0.01)
df_01.head()
このようにデータフレームオブジェクトに対してsample()メソッドを適用し、frac引数に抽出したい割合を指定します。抽出したデータフレームdf_01の要素の数を調べてみると、
len(df_01)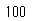
このように10000個の要素をもったデータフレームから1%の100個の要素を抽出することができました。ここでは、ランダムに全体の1%のデータを抽出しました。次に、扱うのは層化抽出です。
層化抽出
母集団を、いくつかの部分母集団にわけることを層化といいます。層化抽出法は、この各部分母集団から標本を抽出する方法です。特に、各層の大きさに比例させて抽出数を配分する方法を比例配分法といいます。
今回はどうぶつたちのなまえで比例配分してみましょう。
# ライブラリのインポート
from sklearn.model_selection import train_test_split
# サンプリング
_,df_02=train_test_split(df,test_size=0.01,stratify=df['なまえ'])
df_02.head()
では、確認していきます。まず、抽出したデータフレームdf_02の要素の数は、
len(df_02)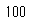
このように全体の1%である100個の要素が抽出できていますね。次に、比例配分できているかを確認しましょう。元のデータフレームでは、どうぶつたちがどのような比率であったか、同じことを無作為抽出、層化抽出(比例配分)で確認してみます。
# 元のデータフレームのどうぶつたちの比率
df_summary=df.groupby('なまえ').agg({'とくてん':'count'}).reset_index().rename(columns={'とくてん':'データの数'})
df_summary['割合']=df_summary['データの数']/df_summary['データの数'].sum()
df_summary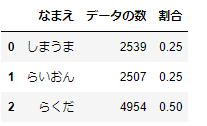
元のデータでは、しまうま:25%、らいおん:25%、らくだ:50%となっています。次に、単純抽出の場合をみてみましょう。
# 単純無作為抽出したときのどうぶつたちの比率
df_01_summary=df_01.groupby('なまえ').agg({'とくてん':'count'}).reset_index().rename(columns={'とくてん':'データの数'})
df_01_summary['割合']=df_01_summary['データの数']/df_01_summary['データの数'].sum()
df_01_summary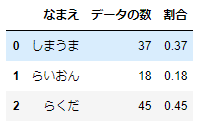
単純無作為抽出した場合は、しまうま:37%、らいおん:18%、らくだ:45%となっています。このように元のデータにおける動物たちの比率はまったく考慮されていません。
次に、層化抽出をみてみましょう。
df_02_summary=df_02.groupby('なまえ').agg({'とくてん':'count'}).reset_index().rename(columns={'とくてん':'データの数'})
df_02_summary['割合']=df_02_summary['データの数']/df_02_summary['データの数'].sum()
df_02_summary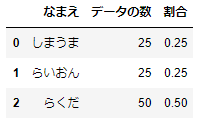
今度は、しまうま:25%、らいおん:25%、らくだ:50%となり、元のデータの比率に一致しています。
まとめ
いかがでしたか?サンプリングするにもいろんな方法があります。実際におこなうときには、どのような方法をとるとよいのか、よく検討することが必要になります。
▶ データ分析をする過程ではまだまだいろんな前処理があります。以下の記事もあわせて参考にしてください。



コメント