
はじめに
今年に入ってシリーズで書いています。Pythonの分析の流れを記載した投稿をさせていただき、この流れに沿った投稿を追加していっています。

分析の流れの「データの概要把握」のプロセスを扱っています。前回は、まずはデータを読み込むところを扱いました。データの読み込みにもいろんなパターンがありましたね。ヘッダがあったり、なかったり、行頭からデータがなく途中から読み込みたい場合など、いろんなパターンを扱いました。

今回は読み込んだデータの概要把握の部分です。まずは、単純にデータをみるところから始めます。
データの準備
今回はpython機械学習のライブラリである、scikit-learnに付属しているiris(アヤメの計測データ)というデータセットを使います。このデータセットの内容を知りたい場合は以下のblogを参考にするとよいかと思います。
このブログの記事には、iris(アヤメの計測データ)以外にもscikit-learnに付属してデータセット(Boston house-prices (ボストン市の住宅価格)やDiabetes (糖尿病患者の診断データ)、Digits (数字の手書き文字)etc)を解説してくれています。今後、機械学習を進めていく中で、本で解説されたデータ以外のデータを試したくなったときに、scikit-learnの付属データセットは重宝すると思うので、一度目を通しておくとよいでしょう。
次のようにしてデータを読み込みます。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_dataset=pd.DataFrame(iris.data, columns=iris.feature_names)まずはデータを眺める
では、さっそくデータを眺めていきましょう。実際のデータを見る際に、まずは先頭の数行をみてみるのがよいでしょう。次のようにhead()を使うと先頭5行のデータを見ることができます。
iris_dataset.head()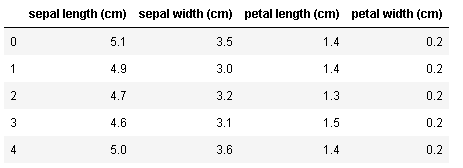
先に紹介したblogにあるように、sepal length、sepal width、petal length、petal widthは次の意味になります。
| sepal length (cm) | がく片の長さ |
|---|---|
| sepal width (cm) | がく片の幅 |
| petal length (cm) | 花弁の長さ |
| petal width (cm) | 花弁の幅 |
これらのデータが1セットで1レコードとなっていますね。head()は引数を与えないと先頭5行を表示しますが、引数で表示させる行数を指定することができます。また、先頭のデータを見るのと同じように、末尾のデータをみることも大切です。先頭のデータはうまく読み込めていたけど、後ろのほうではうまく読み込めていなかった、ということはよくあるので、必ず見る癖をつけておくとよいでしょう。末尾のデータをみるには、tail()を使います。
iris_dataset.tail()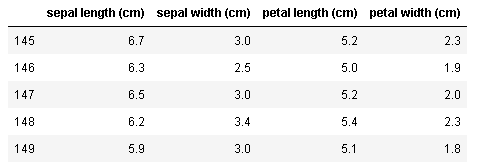
データはうまく読み込めてそうですね。次にデータがどのような形をしているのか、を確認しておきましょう。今回は列数が4つなのですぐにわかるのですが、列数が多いとすぐにはわかりません。このような場合には、shape属性で確認します。
iris_dataset.shape(150, 4)150行、4列のデータであることがわかりました。4つの列があるデータが150行、つまり150レコードあるのですね。次に、各列の情報をもっと詳しく見ていきましょう。次のようにinfo()を使うと、 「有効データ数」「データ型」「メモリ使用量」などの情報を知ることができます。
iris_dataset.info()
今回のデータは150レコードあり、どの列も欠損はなくデータ型はfloat64となっていることがわかります。
まず初めにデータを見るときには、欠損値がないかは重要な確認事項となります。欠損値の数は、info()でnon-null の数がわかるので結果的にわかるのですが、通常は次のようにして明示的に欠損値の数を確認します。
iris_dataset.isnull().sum()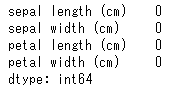
すると、各列ごとに欠損値の数を返してくれます。
基本統計量を求める
次に基本統計量を算出してみましょう。難しいことを在りません。次のようにdescribe()を使うと一瞬で、各種基本統計量を算出して表示してくれます。
iris_dataset.describe()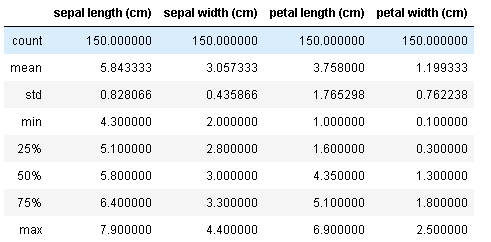
このように、各列ごとにレコード数、平均、標準偏差、最小値、25パーセンタイル、中央値、75パーセンタイル、最大値を算出してくれます。なお、dexcribe()は各列の基本統計量を算出してくれる便利なメソッドですが、オプションを指定しないdefaultの状態では数値だけが算出の対象となります。文字列も対象とする場合は、オプションでinclude=’all’を指定します。また、数値以外の列のみを対象にしたい場合は、exclude=’number’とします。
あと、好みの問題ですが、結果を転置させると見やすいかもしれません。
iris_dataset.describe().T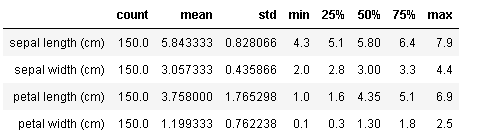
まとめ
いかがでしたでしょうか?今回はデータを取り込んだ後にやる、初めの一歩、データの確認方法を扱いました。次回も、もう少しデータを見ていきたいと思います。
▶ 次にデータの概要を把握しましょう。

コメント