
はじめに
今回も数値データのカテゴリ化を扱います。前回は、、一例として年齢を年代別にカテゴリ化しました。mathライブラリのfloorモジュールは使いましたが、数値データをカテゴリ化する専用の関数は使わずにおこないました。今回は、関数を使ってカテゴリ化する処理を紹介します。
▶ 専用の関数を使わずに数値データをカテゴリ化する方法は以下の記事を参考にしてください。

数値データを任意の境界で区切り、カテゴリデータへ変換する処理をビン分割といいます。pandasには、このビン分割をする方法としてcut()メソッドとqcut()メソッドが用意されています。
cut()メソッドは数値データの「値」をもとにビン分割をおこない、qcut()メソッドは数値データの「量」をもとにビン分割します。順にみていきましょう。
cut()メソッド
今回も年齢を年代別にわけることにしましょう。まずはサンプルデータを作ります。
# ライブラリのインポート
import pandas as pd
import numpy as np
# サンプルデータの作成
age=pd.Series(np.random.randint(0,80,20))
print(list(age))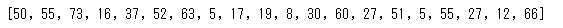
cut()メソッドを使って年代別にビン分割してみましょう。cut()メソッドは第1引数に分割をおこないたい一次元データを与えます(リストでもシリーズでもいけます)。第2引数(bins)はビン分割の区分をリストで与えます。
pd.cut(list(age),bins=[0,10,19,29,39,49,59,69])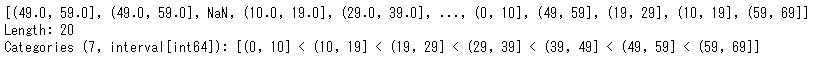
出力は、(は境界を含まず、]は境界を含みます。そのため、一つ目の出力の(49,0,59.0]は、49より大きく59以下を意味します。
次に30歳で2分割してみましょう。29歳以下と30歳以上に分けます。その場合は次のようにします。
pd.cut(list(age),bins=[0,29,70])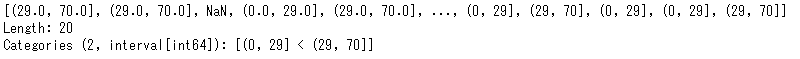
カテゴリ化した各データにラベルをつけることもできます。labels引数でラベルを与えます。
pd.cut(list(age),bins=[0,29,70],labels=['lower','upper'])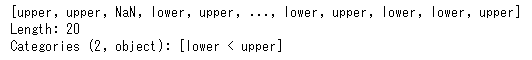
カテゴリ化した各区分領域に属する値を集計することもできます。これは、value_counts()でおこないます。
age_cut=pd.cut(list(age),bins=[0,29,70],labels=['lower','upper'])
age_cut.value_counts()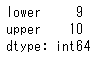
qcut()メソッド
次にqcut()メソッドを確認しておきましょう。qcut()メソッドは「量」をもとにビン分割をおこないます。第2引数qに分割数をまたは文意数を指定します。分割数を指定した場合、各区分領域の要素数が等しくなるような処理がされます。
pd.qcut(list(age),q=2)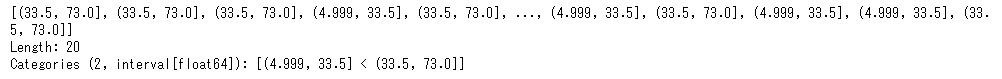
次に分位数を指定する場合です。q分位数をリストで指定します。
pd.qcut(list(age),q=[0,0.25,0.5,0.75,1])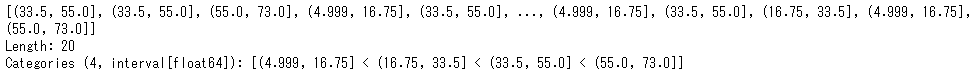
qcut()メソッドでも、cut()メソッドと同様にlabels引数が使えます。やってみましょう。
pd.qcut(list(age),q=2,labels=['lower','upper'])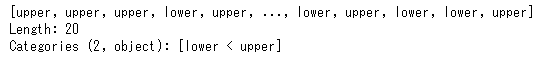
まとめ
いかがでしたか?今回は2つの分割方法をご紹介しました。自分で分けたい区分領域を指定する方法、もう一つは、分割数を指定する方法ですね。分割数を指定する方法では、各区分領域の要素数が等しくなるように分割されます。
▶ 他にもいろんな前処理の記事があります。

コメント