
▶ 縦持ちデータ・横持ちデータの変換を行いたい場合は、以下の投稿をどうぞ

▶ 条件を指定してデータフレームから必要なデータを抽出したい場合は、以下の記事を参考にしてください。

はじめに
今回はpandasのpivot_table()メソッドについて扱います。このブログでは、「縦持ちデータから横持ちデータへの変換」を紹介したときに簡単に触れてます。今回は、pivot_table()メソッドだけをとりあげて、学んでいきましょう。
サンプルデータの作成
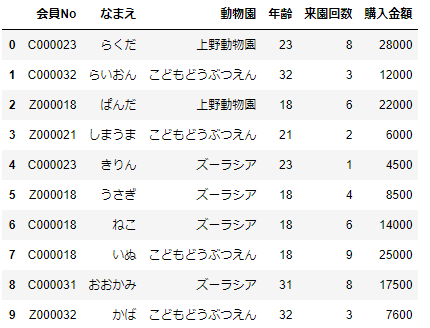
このブログで何度か使っている、どうぶつたちのサンプルデータを使いましょう。以下のコードでデータを作ってください。
# ライブラリのインポート
import pandas as pd
import numpy as np
# 表示設定
pd.options.display.precision = 1
# サンプルデータの作成
df_sample=pd.DataFrame({
'会員No':['C000023','C000032','Z000018','Z000021','C000023','Z000018','C000018','C000018','C000031','Z000032'],
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ','いぬ','おおかみ','かば'],
'動物園':['上野動物園','こどもどうぶつえん','上野動物園','こどもどうぶつえん','ズーラシア','ズーラシア','ズーラシア','こどもどうぶつえん','ズーラシア','こどもどうぶつえん'],
'年齢':[23,32,18,21,23,18,18,18,31,32],
'来園回数':[8,3,6,2,1,4,6,9,8,3],
'購入金額':[28000,12000,22000,6000,4500,8500,14000,25000,17500,7600]
})
df_sample
年齢のところは、「年代」にカテゴリ化しておきましょう。
# 年齢をカテゴリ化
df_sample['年代']=df_sample['年齢'].apply(lambda x:np.floor(x/10) * 10)
df_sample['年代'].replace({10:'10代',20:'20代',30:'30代'},inplace=True)
df_sample=df_sample[['会員No', '動物園','なまえ', '年代','年齢', '来園回数','購入金額']]
df_sample.drop('年齢',inplace=True,axis=1)
df_sample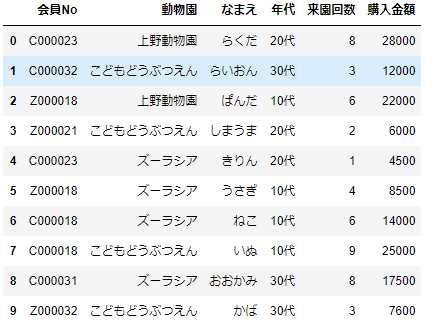
pivot_table()を使ってみる
では、サンプルデータを使ってpivot_table()を試していきましょう。まず、pivot_table()メソッドの基本を整理しておきましょう。必須の引数は以下の3つとなります。
- data:第一引数です。データフレームを指定
- index:行見出しにする変数名を指定
- columns:列見出しにする変数名を指定
この指定をすれば、データフレームの中から、index, columnsで指定されなかった変数のうち、数値をあらわす変数のみが選択されて「平均値」が計算されます。早速、やってみましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園')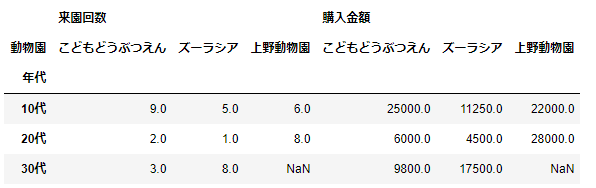
このように、3つの変数を指定するだけで、残りの数値の変数に対して平均値を計算することができました。数値による変数が複数ある場合は、今回の結果のようにその変数の分だけ計算されます。
引数としてvaluesを指定すると、ここで指定した変数だけが計算されるようになります。これもやってみましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園',values='購入金額')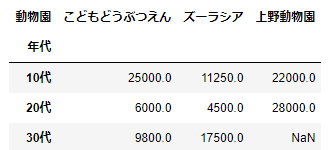
先ほどは、来園回数と購入金額の両方が計算されていましたが、今回はvaluesで指定した購入金額のみが計算されています。
ここまでは、計算方法の指定をしていなかったため、すべて平均値の計算がされていました。引数aggfuncで計算方法を指定することができます。
pd.pivot_table(df_sample,index='年代',columns='動物園',values='購入金額',aggfunc='sum')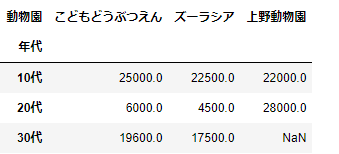
aggfuncをリストで指定すれば、複数の計算方法を指定することもできます。ここでは、meanとsumを指定してみましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園',values='購入金額',aggfunc=['mean','sum'])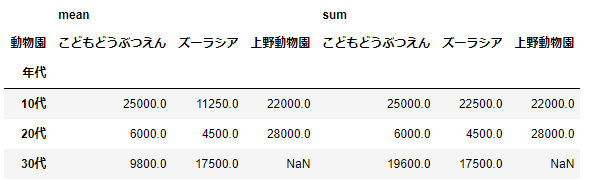
さらに引数marginsで合計の表示/非表示を設定することができる。marginsで合計を指定した場合は、合計の項目名を引数magins_nameで指定することができます。
pd.pivot_table(df_sample,index='年代',columns='動物園',values='購入金額',aggfunc='sum',margins=all, margins_name='合計')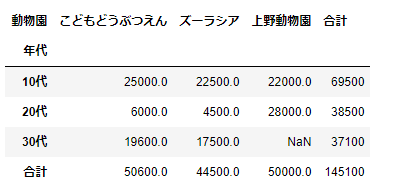
まとめ
いかがでしたか?今回はpivot_table()メソッドについて扱いました。このブログでご紹介するのは遅くなりましたが、よく使うメソッドですね。データの概要把握の時には、よく活躍するメソッドになります。しっかり復習しておきましょう。
▶ ピボットテーブルのさらに詳しい使い方は以下の記事をどうぞ。

コメント