
はじめに
今回は再び、pandasのpivot_table()メソッドを扱います。前回はpivot_table()メソッドの基本的な使い方を学びました。今回も基本的な使い方ですが、前回扱えなかった部分を補足するようにします。前回の内容は以下を参照下さい。

サンプルデータ
サンプルデータは、前回のpivot_tableの記事と同じものとしましょう。以下のコードで定義します。
# ライブラリのインポート
import pandas as pd
import numpy as np
# サンプルデータの作成
df_sample=pd.DataFrame({
'会員No':['C000023','C000032','Z000018','Z000021','C000023','Z000018','C000018','C000018','C000031','Z000032'],
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ','いぬ','おおかみ','かば'],
'動物園':['上野動物園','こどもどうぶつえん','上野動物園','こどもどうぶつえん','ズーラシア','ズーラシア','ズーラシア','こどもどうぶつえん','ズーラシア','こどもどうぶつえん'],
'年齢':[23,32,18,21,23,18,18,18,31,32],
'来園回数':[8,3,6,2,1,4,6,9,8,3],
'購入金額':[28000,12000,22000,6000,4500,8500,14000,25000,17500,7600]
})
# 年齢をカテゴリ化
df_sample['年代']=df_sample['年齢'].apply(lambda x:np.floor(x/10) * 10)
df_sample['年代'].replace({10:'10代',20:'20代',30:'30代'},inplace=True)
df_sample=df_sample[['会員No', '動物園','なまえ', '年代','年齢', '来園回数','購入金額']]
df_sample.drop('年齢',inplace=True,axis=1)
display(df_sample.head(2))
pivot_table()のいろんな使い方
基本
まずは、基本的な使い方です。前回の投稿でも扱いましたが
- data:データフレーム
- index:行見出しに表示する項目
- colums:列見出しに表示する項目
- values:集計する項目
- aggfunc:適用する関数
を指定することが基本となります。これらは必ずしも全部指定する必要はなく、省略することもできます。いろんなパターンをみていきましょう。
indexとcolumnsを指定する
まずは簡単なものから見ていきましょう。indexとcolumnsだけを指定すると、指定していない列のうち数値列を対象として平均が算出されます。やってみましょう。ここでは、indexとして「年代」, clumnsとして「動物園」を指定しています。
pd.pivot_table(df_sample,index='年代',columns='動物園')
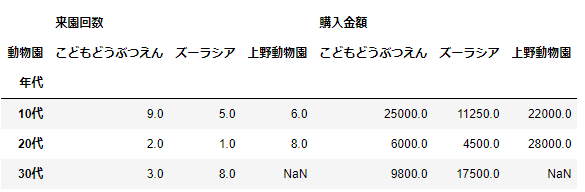
indexとcolumnsに「年代」と「動物園」を指定したので、残る数値列は「来園回数」と「購入金額」となります。この2つの項目の平均が集計されています。よくみると、集計結果にNaNがあります。集計結果のNaNを置き換えるオプションもあります。fill_valueオプションを指定してみましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園',fill_value='なし')
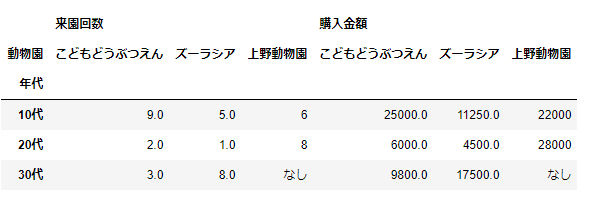
valuesを指定する
先ほどは、indexとcolumnsだけを指定して、残る数値列が自動的にvaluesに指定されていました。ただ、集計が不要なケースもありますね。そのような場合は、必要な列だけを指定します。今回は「来園回数」のみを指定してみましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園',values='来園回数',fill_value='なし')
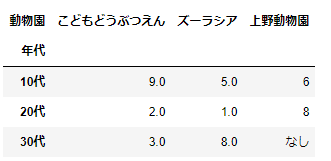
これだと何が集計されたのかがわからない、というのであれば次のようにするとよいです。
pd.pivot_table(df_sample,index='年代',columns='動物園',values=['来園回数'],fill_value='なし')
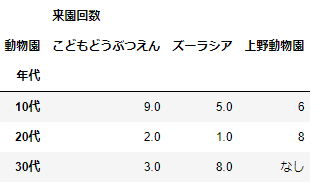
これはmultiindexとなっています。
aggfuncを指定する
何も指定しない場合は、平均値が算出されますが、これも指定をすることができます。ここでは購入金額をcountしてみましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園',values=['購入金額'],fill_value='なし',aggfunc=['count'])
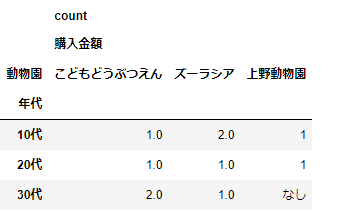
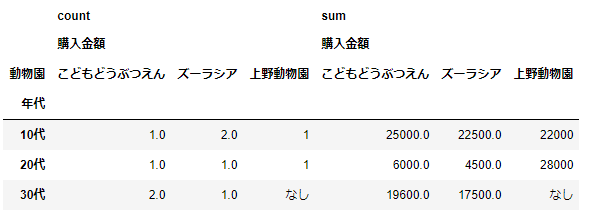
次に複数の集計方法を指定した場合をみてみましょう。countに加えて、sumも指定しましょう。
pd.pivot_table(df_sample,index='年代',columns='動物園',values=['購入金額'],fill_value='なし',aggfunc=['count','sum'])
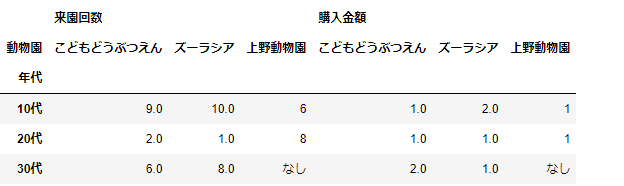
項目ごとに集計内容を変える場合
pd.pivot_table(df_sample,index='年代',columns='動物園',values=['購入金額','来園回数'],fill_value='なし',
aggfunc={
'購入金額':'count',
'来園回数':'sum'
})
まとめ
いかがでしたか?今回はピボットテーブルのいろんなパターンをみてみました。整理してみると簡単ですね!是非身につけて、データ分析に活かしましょう!
▶ クロス集計した際の注意点をまとめています。以下も参考にしてください。


コメント