
▶ 条件を指定してデータフレームから必要なデータを抽出したい場合は、以下の記事を参考にしてください。

はじめに
テーブルデータには、「横持ち(wide)」と「縦持ち(long)」と呼ばれる2つの形式があります。今回はこの横持ち/縦持ちデータを扱います。データ形式を理解したうえで、pandasを使ってデータ変形ができるようになりましょう。
データ形式が横持ちの状態は次のような状態を指します。それぞれ従業員の属性(出身地や年齢、性別など)を横方向に持つデータフォーマットです。データが横持ちの場合、視覚的に見やすいです。
現場で使える! PANDASデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法
| 従業員名 | 出身地 | 年齢 | 性別 |
| A | Tokyo | 28 | M |
| B | Osaka | 32 | F |
この横持ちのデータを縦持ちのデータに変換したのが次の表です。
| 従業員名 | 項目名 | 値 |
| A | 出身地 | Tokyo |
| A | 年齢 | 28 |
| A | 性別 | M |
| B | 出身地 | Osaka |
| B | 年齢 | 32 |
| B | 性別 | F |
横持ちデータは1行が1従業員を表していましたが、縦持ちのデータは1従業員が複数行に分けられます。各従業員の属性は「項目名」の列で示され、各項目に対応する値を持ちます。
縦持ちから横持ちへ変形
サンプルデータの作成
data=[
['A','出身地','Tokyo'],
['A','年齢',28],
['A','性別','M'],
['B','出身地','Osaka'],
['B','年齢',32],
['B','性別','F']
]
df_long=pd.DataFrame(data,columns=['name','attribute','value'])
df_long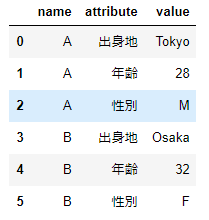
縦持ちから横持ちへ変形
データを縦持ちフォーマットから横持ちフォーマットへ変換するにはデータフレームのpivotメソッドを使います。pivotメソッドは縦持ちから横持ちなどデータ構造の変換をおこないますが、変換されたデータをピボットテーブルと呼びます。
pivotメソッドの第一引数indexはピボットテーブルで使うインデックスラベルを指定、第二引数columnsはピボットテーブルで使うカラムを指定します。pivotメソッドはデータフレームを任意の形で変換します。
df_long.pivot(index='name',columns='attribute')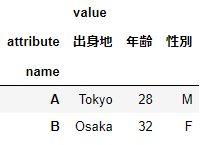
縦持ちであったdf_longが横持ちのフォーマットへ変換されています。カラムラベルは階層型インデックスとなります。
オプションのvalues引数で変換したデータフレームの値を指定することも可能です。データフレームdf_longへ0か1の値を持つflagカラムを追加しましょう。values引数へflagを指定して、フラグの値を持つピボットテーブルを作成します。
# flag列の追加
df_long['flag']=[1,1,0,0,1,1]
df_long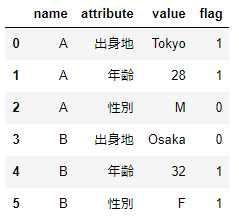
# values引数にflagを指定
df_long.pivot(index='name',columns='attribute',values='flag')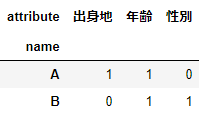
pivot_tableメソッドとpivotメソッドは混同しやすいので注意しましょう。pivot_tableメソッドは数値データの集計を扱うためデータフレームに重複したインデックスまたはカラムがあっても集計してピボットテーブルを戻します。一方で、pivotメソッドでは重複したインデックスとカラムがある場合はValueErrorとなります。
横持ちから縦持ちへ変形
サンプルデータの作成
data=[
['A','Tokyo',28,'M'],
['B','Osaka',32,'F']
]
df_wide=pd.DataFrame(data,columns=['name','出身地','年齢','性別'])
df_wide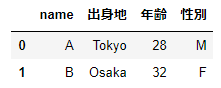
横持ちから縦持ちへ変形
横持ちから縦持ちへの変形はmeltメソッドを使います。meltメソッドの第一引数id_varsへ識別可能な値を持つカラムを指定します。id_varsへ指定されたカラムの値を基に、他のカラムのラベルをカラムvariableへ、そのカラムの値をカラムvalueへ展開します。
df_wide.melt(id_vars='name')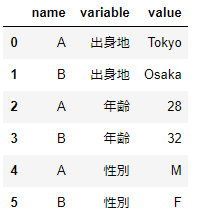
meltメソッドで展開されたデータフレームのvariableとvalueのカラムラベルを文字列で指定することも可能です。variableはvar_name引数へ、valueはvalue_name引数へそれぞれラベルを指定します。
df_wide.melt(id_vars='name',var_name='項目名',value_name='値')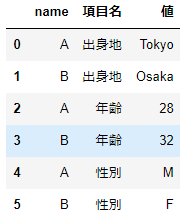
value_vars引数は展開されたデータフレームに含める値を指定することができます。リストを使い複数カラムを指定することも可能です。
df_wide.melt(id_vars='name',value_vars=['出身地','年齢'])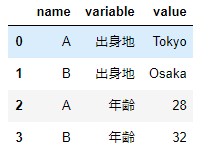
まとめ
いかがでしょうか?今回は、横持ちデータ、縦持ちデータを相互に変換する方法を扱いました。知らないと、どうしたらよいんだろう?と悩んでしまいますが、知ってしまえば、なんということはないですね。しっかり身に着けておきましょう。
▶ 順位付けをするrank( )メソッドを解説した記事はこちらになります。

コメント