
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ matplotlibによる可視化を基本から解説しています。以下の投稿も合わせてご覧ください。

はじめに
今回はgroupbyでデータをグループ分けして処理した結果を描画してみましょう。データの概要を把握するときには、グループごとの特徴を把握するために集計しますよね。これを比較するときにただ値を見るだけでなく、可視化するとよりわかりやすくなります。さっそくやっていきましょう。
groupbyの集計結果を可視化する
サンプルデータの準備
今回はseabornにあらかじめ準備されている学習用データセットの「flights」を利用することにしましょう。
# ライブラリのインポート
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
df = sns.load_dataset('flights')
df.head()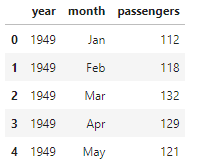
年月ごとの飛行機の乗客のデータですね。基本統計量だけ確認しておきましょう。
# 基本統計量の確認
df.describe().T
yearをみると1949年から1960年までのデータがあるようです。yearもpassenngersも144個のデータがあります。念のため欠損値を確認しておくと、
# 欠損値の確認
df.isna().sum(axis=0)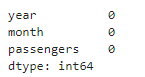
欠損値もないことが確認できました。では、年ごとの乗客数の平均を算出して可視化してみることにしましょう。
年ごとの集計と可視化
年ごとの乗客数の平均を求めてみましょう。既にgroupbyの使い方を扱っているので簡単ですね。
▶ groupbyの使い方を復習する場合は以下の記事をどうぞ。

# 年ごとの乗客数の平均
df.groupby('year').mean()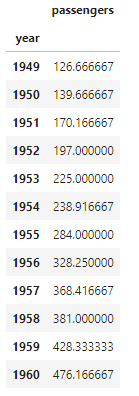
簡単ですね。groupby()で集計すると、groupbyで軸とした項目がインデックスになります。そのためこの可視化は非常に簡単です。plt.plot(x,y)で折れ線グラフを描画できますが、xを省略すると横軸がインデックスになるのでしたね。なので、これを描画するには次のようにできます。
# 年ごとの乗客数の平均
plt.plot(df.groupby('year').mean())
plt.grid()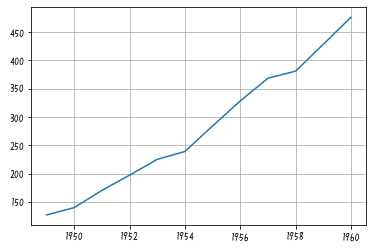
驚くほど簡単ですね。このようにgroupbyで指定した項目をx軸とする折れ線は簡単に描くことができます。
まとめ
今回はgroupbyで処理した結果を直接描画する方法を扱いました。1行のコードで一発で可視化できるのは便利ですよね。どんどん使っていきましょう。
コメント