
<データ分析>:初学者向けの超基礎的な記事もあります。是非合わせてお読みください。
▶ データ分析のための環境構築(Windows編)
▶ データフレーム型としてcsvファイルを読み込む方法
はじめに
今回はデータフレームを参照するときに用いる、loc, ilocプロパティを扱います。pandasを扱う上では必須の操作になるので、是非、身に着けておきましょう。簡単ですが、いくつかのパターンがあるので整理しておきます。
サンプルデータの作成
サンプルデータは前回と同じものを使うことにしましょう。以下のコードでサンプルデータを作成してください。
# ライブラリのインポート
import pandas as pd
import datetime as dt
import random
pd.options.display.precision=0
# 年月マスタの準備
month_list=pd.date_range('2019-04',periods=12,freq='M')
months=[]
for month in month_list:
months.append(month.strftime('%Y-%m'))
# どうぶつマスタの準備
animals=['らくだ','ぱんだ','きりん','ぞう','こぎつね','ねこ']
# サンプルデータの作成
df_sample=pd.DataFrame({
'年月':random.choices(months,k=200),
'どうぶつ':random.choices(animals,k=200),
'年齢':[random.randint(18,69) for i in range(200)],
'単価':random.choices([1200,1800,2500],k=200),
'個数':random.choices([1,2,3,4,5],k=200)
})
# 売上の作成
df_sample['売上']=df_sample['単価']*df_sample['個数']
df_sample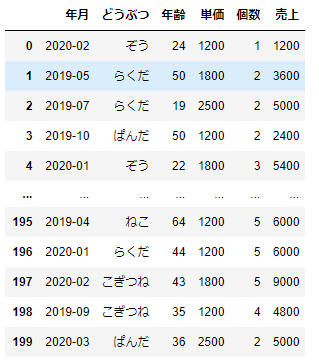
loc
locは、行と列を「行ラベル」「列ラベル」で指定します。やってみましょう。このサンプルデータでは、行ラベルの設定がないため、次のように行は数字で指定します。
df_sample.loc[0:2,['年月','どうぶつ','年齢']]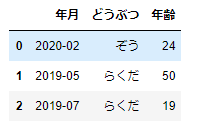
locの行指定は、「行ラベル」で指定できます。行ラベルが設定されたデータでやってみましょう。
df_sample2=pd.pivot_table(data=df_sample,index='年月',columns=['どうぶつ'],values='売上')
df_sample2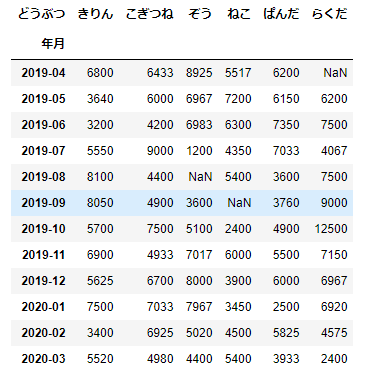
このデータは、行ラベルに「年月」が指定されています。この場合は、次のように行ラベルを指定してデータを参照することができます。
df_sample2.loc['2019-04':'2019-07','ねこ':'らくだ']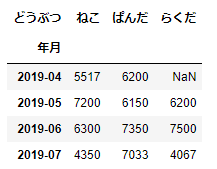
実は、locは行ラベルだけを指定することもできます。
df_sample2.loc[['2019-04']]
条件式を指定することもできます。
df_sample.loc[df_sample['売上']>3000]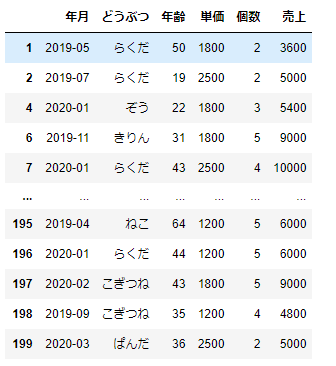
iloc
ilocは行と列を「行番号」「列番号」で指定します。次のように使うことができます。
df_sample.iloc[0:5,0:3]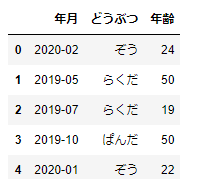
上記では、行番号、列番号の両方を指定していますが、行番号のみの指定もできます。
df_sample.iloc[0:5]
まとめ
いかがでしたか?わたしは、行ラベルが設定されていないサンプルデータで数字で行が指定されているのを見て、誤解してました。また、locのあとに条件式のみを指定しているケースなどで混乱していました。整理してみると簡単ですね。
データを入手したらまず、ざっと眺めて概要を把握することが大切です。データの概要把握については以下を参照してください。

コメント
df_sample2.loc[‘2019-04′:’2019-07′,’どうぶつ’:’売上’]
では、何故 ’きりん’,’こぎつね’,’ぞう’ は表示されないのでしょうか?
evaさん
ご質問ありがとうございます。
記載していたコードで何故か動いてしまうのですが、もともと意図していたものと異なっておりました。
当方のミスにより混乱させてしまって申し訳ありません。
locにより、ラベルで指定できることを記載したかったので、
df_sample2.loc[‘2019-04′:’2019-07′,’ねこ’:’らくだ’]
と記載すべきでした。
大変申し訳ありません。投稿も訂正させていただきます。