
はじめに
今回はgroupbyの使い方を整理します。このブログでも何度かグループ化を扱ってきましたが、いくつかの使い方や表記方法があるので整理しておきましょう。グループ化はデータ分析するうえでも必須となるので、抑えておきましょう。
サンプルデータの作成
まずはサンプルデータを作っていきましょう。どうぶつのお客様の購買データをつくっていきましょう。期間は2019/4~2020/3としましょう。どうぶつのお客様はらくだ, ぱんだ, きりん,ぞう, こぎつね, ねこ、このお店の商品は1200円,1800円,2500円の商品があるとしましょう。
# ライブラリのインポート
import pandas as pd
import datetime as dt
import random
pd.options.display.precision=0
# 年月マスタの準備
month_list=pd.date_range('2019-04',periods=12,freq='M')
months=[]
for month in month_list:
months.append(month.strftime('%Y-%m'))
# どうぶつマスタの準備
animals=['らくだ','ぱんだ','きりん','ぞう','こぎつね','ねこ']
# サンプルデータの作成
df_sample=pd.DataFrame({
'年月':random.choices(months,k=200),
'どうぶつ':random.choices(animals,k=200),
'年齢':[random.randint(18,69) for i in range(200)],
'単価':random.choices([1200,1800,2500],k=200),
'個数':random.choices([1,2,3,4,5],k=200)
})
# 売上の作成
df_sample['売上']=df_sample['単価']*df_sample['個数']
df_sample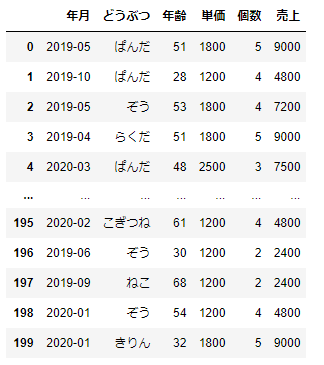
groupbyの使い方
基本的な使い方
データフレームオブジェクトに対して、groupby(‘列名’)のように列名を指定すると、groupbyオブジェクトを作成することができます。このgroupbyオブジェクトに、メソッドを指定することでグループごとの演算をすることができます。早速やってみましょう。
df_sample[['年月','売上']].groupby('年月').sum()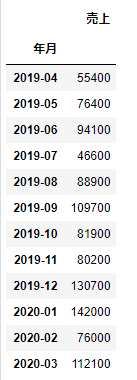
groupbyオブジェクトにメソッドを適用した場合、デフォルトでグループラベルがインデックスになります。グループラベルをインデックスにしたくないときには、次のようにas_index=Falseを指定します。
df_sample[['年月','売上']].groupby('年月',as_index=False).sum()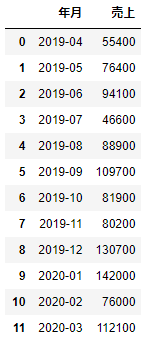
複数の列に関数を適用する
上記の例では「売上」にsum()を適用しています。次は、複数の列に異なるメソッドを指定してみましょう。
df_sample.groupby('年月',as_index=False).agg({'個数':'mean','売上':'sum'}).rename(columns={'個数':'平均個数','売上':'月間売上'})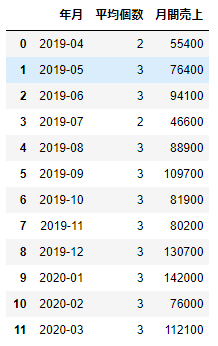
groupbyで演算をおこなったときには、処理した列名がそのまま適用されるため、rename()の部分で分かりやすい列名に書き換えています。この例のように、列と適用したいメソッドを辞書のように対で指定することで、複数の列を指定してメソッドを適用することができます。
1つの列に複数の関数を適用する
1つの列に複数のメソッドを適用する場合は、次のようにメソッドの指定時にリストで指定します。
df_sample.groupby('年月',as_index=False).agg({'売上':['mean','sum']})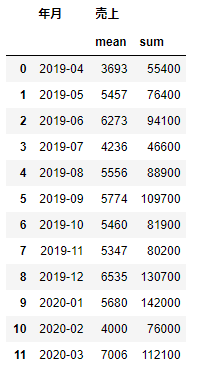
簡易的な表記
1つの列にメソッドを適用するのであれば次のように記述することもできます。
df_sample.groupby('年月',as_index=False).売上.sum()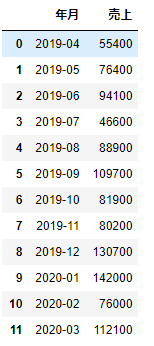
このようにgroupby()のあとに、「.」で列名をつないで、さらにメソッドを指定する、という記述もできます。
さらに、次のように複数のメソッドを適用することができます。
df_sample.groupby('年月',as_index=False).売上.agg(['sum','mean'])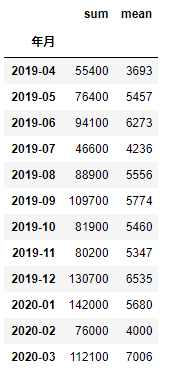
この場合は、as_index=Falseが効いていませんね。(なんでだろ?誰か教えてください)次のようにreset_index()とすると、年月部分をインデックスとせずに処理することができます。
df_sample.groupby('年月').売上.agg(['sum','mean']).reset_index()まとめ
いかがでしょうか?使い慣れている方にとっては、きっと簡単でしたね。わたしはいつも似たような処理しかしてなかったので、ちょっと違うパターンをみたときには、こんな書き方もあるんだ?って感動しました!
コメント