
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ 初学者向けにデータ分析に関する記事を書いています

はじめに
これまでTitanicのデータセットを使ってLightGBMでのモデル構築をしてきました。はじめは「Pclass」「Fare」を数値データとして扱い、この2つの特徴量のみでモデル構築をしていました。今回はLightGBMでカテゴリ変数を扱う方法を解説します。また前回、数値データとした「Pclass」を今回はカテゴリ変数として扱うことにします。
今回はscikit-learn APIでの実装とします。前回のscikit-learn APIでのモデル構築は以下の記事をご覧ください。

事前準備
今回も「Titanic」のデータセットを使います。このデータセットはKaggleで提供されています。「Titanic – Machine Learning from Disaster」というコンペの「Data」タブから入手することができます。
データの読み込みまでの工程は前回と全く同じですが、再掲しておきます。
#ライブラリのインポート
import numpy as np
import pandas as pd
import os
import matplotlib
import seaborn as sns
# モデリング
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
# ディレクトリの設定
INPUT_DIR = './Input'
OUTPUT_DIR = './Output'
os.makedirs(OUTPUT_DIR, exist_ok=True)
# データの読み込み
df_train = pd.read_csv(f'{INPUT_DIR}/train.csv')
df_train.head(3)
scikit-learn APIを使ってLight GBMのモデルを作る
説明変数と目的変数の準備
前回のTitanicデータでLightGBMのモデル構築をした際は「Pclass」「Fare」をともに数値として扱いました。今回はカテゴリ変数も加えることにしましょう。と言っても、実は、LightGBMでカテゴリ変数を扱うのはとっても簡単です。カテゴリ変数に対する特別な処理は、すべてLightGBM側で実行してくれます。なので、カテゴリ変数であることを明示的に示すだけです。
今回は「Pclass」「Sex」「Embarked」をカテゴリ変数として扱い、「Fare」と「Age」を数値データとします。型の変更は以下のようにastypeを使うと簡単です。
# 説明変数と目的変数
df_train['Pclass'] = df_train['Pclass'].astype('category')
df_train['Sex'] = df_train['Sex'].astype('category')
df_train['Embarked'] = df_train['Embarked'].astype('category')
feature_names = ['Pclass', 'Fare', 'Sex', 'Age', 'Embarked']
categorical_features = ['Pclass', 'Sex', 'Embarked']
X, y= df_train[feature_names], df_train[['Survived']]
print('説明変数と目的変数のデータの形状')
print(X.shape, y.shape)
# train用とvalidation用のデータセットに分割
X_train, X_validation, y_train, y_validation = train_test_split(X, y, test_size=0.2,random_state=0)
print('train/validation分割後の説明変数と目的変数のデータの形状')
print(X_train.shape, y_train.shape, X_validation.shape, y_validation.shape)
カテゴリ変数をcategorical_featuresとして変数に格納しているのは、モデルの学習時にカテゴリ変数を明示する必要があるため、その準備となります。
実はLightGBMで「カテゴリ変数を特徴量に加える」としたもののカテゴリ変数を明示するだけの操作となります。
ハイパーパラメータを準備する
ハイパーパラメータの設定などは、これまで変わりありません。前回と同じパラメータの設定をしておきましょう。
# パラメータの準備
params = {
'boosting_type':'gbdt',
'objective':'binary',
'metric':'auc',
'num_leaves':16,
'learning_rate':0.1,
'n_estimators':100000,
'random_state':0
}LGBMのインスタンスを作る
次にインスタンスの作成です。これも変更ありません。Scikit-learn APIではこれまでの機械学習のモデル構築と同様に扱えるので簡単ですね。
# インスタンスの作成
clf = lgb.LGBMClassifier(**params)fit()で学習する
学習もいままでとほとんど変わりません。1つだけ、カテゴリ変数を明示するコード、「categorical_feature = categorical_features」を追加するだけです。
# モデルの学習
clf.fit(
X_train,
y_train,
eval_set = [(X_train, y_train),(X_validation, y_validation)],
categorical_feature = categorical_features,
early_stopping_rounds=100)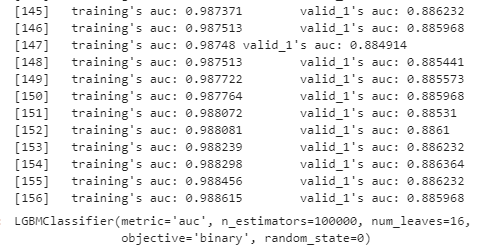
今回、私の環境は156回目で学習が停止となりました。early_stopping_roundsに100を指定しているので、56回目の学習以降100回連続で評価指標の改善が見られなかった、ということですね。
予測と評価
最後に評価しておきましょう。前回、「Pclass」と「Fare」をともに数値データとして扱った際には、訓練データ:0.74298 , 検証データ:0.74302の正解率でした。改善しているでしょうか?
# モデルを使って訓練データ・検証データを予測
y_tr_pred = clf.predict(X_train)
y_va_pred = clf.predict(X_validation)
y_tr_pred = y_tr_pred.round(0)
y_va_pred = y_va_pred.round(0)
# 訓練データ・検証データのaccuracyでの評価
accuracy_tr = accuracy_score(y_tr_pred,y_train)
accuracy_va = accuracy_score(y_va_pred,y_validation)
print(f'[accuracy]訓練データ:{accuracy_tr:.5f} 検証データ:{accuracy_va:.5f}')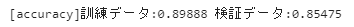
まとめ
今回は学習に使用する特徴量を増やしてモデル構築を行いました。LightGBMでカテゴリ変数を扱う際には明示的に示す必要があります。といっても、「categorical_feature」にカテゴリ変数のリストを指定するだけです。これだけで、他のアルゴリズムのときにおこなったカテゴリ変数の面倒な前処理が不要というのはありがたいですね。
コメント