
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ 初学者向けにデータ分析に関する記事を書いています

はじめに
前回はLightGBMを始めて使う際に戸惑うポイントを整理して、Training APIを使ったモデル構築をおこないました。今回はscikit-learn APIを使ったモデル構築を解説します。この記事を読み終えると、LightGBMでのモデル作成ができるようになります。
▶ Training APIを使ったモデル構築をしたい方は以下の記事をご覧ください。

事前準備
今回も前回と同様「Titanic」のデータセットを使うことにしましょう。このデータセットはKaggleで提供されています。「Titanic – Machine Learning from Disaster」というコンペの「Data」タブから入手することができます。
データの読み込みまでの工程は前回と全く同じですが、再掲しておきます。
#ライブラリのインポート
import numpy as np
import pandas as pd
import os
import matplotlib
import seaborn as sns
# モデリング
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
# ディレクトリの設定
INPUT_DIR = './Input'
OUTPUT_DIR = './Output'
os.makedirs(OUTPUT_DIR, exist_ok=True)
# データの読み込み
df_train = pd.read_csv(f'{INPUT_DIR}/train.csv')
df_train.head(3)
# 説明変数と目的変数
feature_names = ['Pclass', 'Fare']
X, y= df_train[feature_names], df_train[['Survived']]
print('説明変数と目的変数のデータの形状')
print(X.shape, y.shape)
# train用とvalidation用のデータセットに分割
X_train, X_validation, y_train, y_validation = train_test_split(X, y, test_size=0.2,random_state=0)
print('train/validation分割後の説明変数と目的変数のデータの形状')
print(X_train.shape, y_train.shape, X_validation.shape, y_validation.shape)
今回もデータの前処理や特徴量生成の工程をすっ飛ばして、「Pclass」「Fare」「Age」の列のみを使ってモデル構築をしていきます。
ここまでは前回のコードと全く同じです。training APIを使ったモデル構築は以下をご覧ください。
scikit-learn APIを使ってLight GBMのモデルを作る
scikit-learn APIの使い方の概要
まずはscikit-learn APIの使い方の概要をまとめておきましょう。以下のようになります。
ハイパーパラメータを準備する
ハイパーパラメータを準備します。前回、同様のパラメータ設定としましょう。以下のように辞書型で定義します。
# パラメータの準備
params = {
'boosting_type':'gbdt',
'objective':'binary',
'metric':'auc',
'num_leaves':16,
'learning_rate':0.1,
'n_estimators':100000,
'random_state':0
}LGBMのインスタンスを作る
インスタンスを作って学習→予測とするのは、scikit-learnのやり方ですね。インスタンス作成時に先ほど作成したハイパーパラメータの辞書を渡します。LGBMのインスタンスは、回帰問題のときには「lgb.LGBMRegressor 」、分類問題の時には「lgb.LGBMClassifier」とします。今回のタイタニックは乗客の生存を予測する分類問題なので、LGBMClassifierを使います。
# インスタンスの作成
clf = lgb.LGBMClassifier(**params)**paramsとすると、先ほど定義したパラメータの辞書がアンパックされてLGBMClassifier()に渡されます。この辺がわからない場合は以下の記事をご覧ください。

fit()で学習する
# モデルの学習
clf.fit(
X_train,
y_train,
eval_set = [(X_train, y_train),(X_validation, y_validation)],
early_stopping_rounds=100)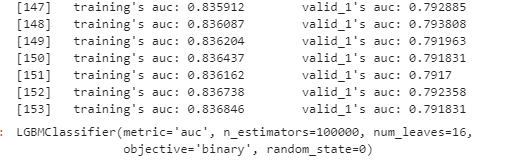
上記のように実行ログとともに学習が進行します。私の環境では153回目で学習が停止となりました。early_stopping_roundsに100を指定しているので、53回目の学習以降100回連続で評価指標の改善が見られなかった、ということでしょう。確認しておきましょう。LightGBMでは「best_iteration_」で一番良い結果となったiterationを確認することができます。
clf.best_iteration_
53回目のイテレーションが評価指標の最高スコアとなっていますね。次に予測と評価です。
予測と評価
学習データ・検証データでそれぞれaccuracy(正解率)を算出してみましょう。
# モデルを使って訓練データ・検証データを予測
y_tr_pred = clf.predict(X_train)
y_va_pred = clf.predict(X_validation)
y_tr_pred = y_tr_pred.round(0)
y_va_pred = y_va_pred.round(0)
# 訓練データ・検証データのaccuracyでの評価
accuracy_tr = accuracy_score(y_tr_pred,y_train)
accuracy_va = accuracy_score(y_va_pred,y_validation)
print(f'[accuracy]訓練データ:{accuracy_tr:.5f} 検証データ:{accuracy_va:.5f}')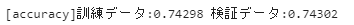
前回行ったTraining APIでモデル構築したときと全く同じ結果になりますね。前回は、このあとに混同行列なども確認をしましたが、まったく同じ結果となるので、今回は割愛することにします。
まとめ
今回はscikit-learn APIを使ってモデル構築をおこないました。Training APIと多少異なる点がありますが、scikit-learnに慣れている方なら、割とすんなり利用できそうですね。今後は、ここまで端折ってきた、カテゴリ変数がある場合の前処理、特徴量生成や特徴量の重要度をみる方法などを確認していきましょう。
コメント