
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ 初学者向けにデータ分析に関する記事を書いています

はじめに
前回のLightGBMでのモデル構築は、始めて実装する方向けに特徴量は数値で3つのみ、ホールドアウト検証としていました。今回はクロスバリデーションの場合を確認していきましょう。基本的にはホールドアウト検証と同じですが、ループ処理が入ります。
k分割交差検証
データをk個のグループに分けてk個のうちの一つのグループをテストデータとして、残りのグループのデータを学習データとします。すべてのグループが必ず1回テストデータとなるようにk回繰り返します。書式を確認しておきましょう。
n_splitsでデータをいくつのグループに分割するかを指定します。defaultでは5となっています。次にshuffleはTrueとすると、ランダムにデータを選択します。random_stateは乱数のシードの指定ですが、再現できるように指定しておくとよいでしょう。
インスタンス作成後は、split()をコールすると実際にデータが分割されます。インスタンスをcvとすると次の書式です。
このように指定すると、ジェネレータが生成されます。ジェネレータからは学習に使うデータのインデックスのリストとテストに使うデータのインデックスのリストを抽出することができます。KFoldの場合はyは省略できます。
for train_idx, test_idx in cv.split(X_train, y_train):
print(f'train_idx:{train_idx},test_idx:{test_idx}')層状K分割交差検証
目的変数のクラス割合を担保しながらデータの分割をおこなうことができます。引数はKFoldの場合と変わりません。以下の書式となります。
作成したインスタンスでsplitをコールしてジェネレータを作る操作もKFoldの場合と同じとなります。インスタンスをcvとすると次の書式です。
層状K分割交差検証を使ったモデル構築
今回は交差検証の中でも「層状K分割交差検証」でのモデル構築をやってみましょう。交差検証以外の部分は前回・前々回と同様になります。
事前準備
#ライブラリのインポート
import numpy as np
import pandas as pd
import os
import matplotlib
import seaborn as sns
# モデリング
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
# ディレクトリの設定
INPUT_DIR = './Input'
OUTPUT_DIR = './Output'
os.makedirs(OUTPUT_DIR, exist_ok=True)
# データの読み込み
df_train = pd.read_csv(f'{INPUT_DIR}/train.csv')
df_train.head(3)
# 説明変数と目的変数
feature_names = ['Pclass', 'Fare']
X, y= df_train[feature_names], df_train[['Survived']]
print('説明変数と目的変数のデータの形状')
print(X.shape, y.shape)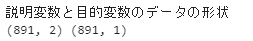
ハイパーパラメータを準備する
# パラメータの準備
params = {
'boosting_type':'gbdt',
'objective':'binary',
'metric':'auc',
'num_leaves':16,
'learning_rate':0.1,
'n_estimators':100000,
'random_state':0
}fit()で学習する
今回は層状K分割交差検証を使ったモデル構築をします。層状K分割交差検証の書式は既に確認しましたね。インスタンスを作ってsplit(X,y)とすることでジェネレータが作成されるのでfor文でループ処理をしていきます。
# 評価指標を格納するリストを準備
metrics = []
# 分割数の指定
n_splits = 5
# StratifiedKFoldクラスのインスタンスを作成
cv = StratifiedKFold(n_splits=n_splits, shuffle=True,random_state=0)
# 交差検証
for fold_id,(train_index, valid_index) in enumerate(cv.split(X,y)):
X_tr = X.loc[train_index,:]
X_va = X.loc[valid_index,:]
y_tr = y.loc[train_index]
y_va = y.loc[valid_index]
model = lgb.LGBMClassifier(**params)
print('*'*70)
model.fit(X_tr,
y_tr,
eval_set=[(X_tr,y_tr),(X_va,y_va)],
early_stopping_rounds=100,
verbose=100
)
y_tr_pred = model.predict(X_tr)
y_va_pred = model.predict(X_va)
metric_tr = accuracy_score(y_tr,y_tr_pred)
metric_va = accuracy_score(y_va,y_va_pred)
metrics.append([fold_id,metric_tr,metric_va])
metrics = np.array(metrics)
print('*'*70)
print(metrics)
print('*'*70)
print('[accuracy]訓練データ:{:.2f}+-{:.2f} 検証データ:{:.2f}+-{:.2f}'.\
format(metrics[:,1].mean(),metrics[:,1].std(),metrics[:,2].mean(),metrics[:,2].std()))
k=5なのでデータを5つのグループに分けています。各グループが1回ずつ検証データとなり、検証データ以外のデータは学習に使います。そのため5回ループを回すことになります。各ループでモデルを構築して、学習データ・検証データの評価結果である「metrics_tr」「metrics_va」をmetricsというリストに格納しています。このとき、どのループによる評価結果であるかわかるように「fold_id」とともにデータを格納しています。
最終的な結果を5回の平均±標準偏差で表示しています。今回は訓練データでの正解率は0.76±0.03, 検証データでの正解率は0.70±0.03という結果となりました。
まとめ
今回は層状K分割交差検証でLightGBMのモデル構築をしてみました。LightGBMや交差検証の部分はなかなか難しかったのではないでしょうか?私もはじめてみたときはちんぷんかんぷんでした。少しでも理解しやすいように、いろんな要素を詰め込まずに分解して、実際に自分でコードを動かして試しながら学習するとよいと思います。
たとえば、LightGBMでは2つのAPIがありました。この違いを理解したうえでどちらかのAPIでの実装とします。また、初めての場合は数値の特徴量のみを採用するのもわかりやすくなると思います。また学習時に、はじめはホールド検証としておいて、そのあとに交差検証をやると理解しやすいかと思います。
コメント