
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ 初学者向けにデータ分析に関する記事を書いています

はじめに
今回はLightGBMを始めて使う方向けに、戸惑うポイントを整理しながら実際にLightGBMでのモデル構築をしていきましょう。今回は前処理や特徴量選択は最小限として、まず動くモデルを作ることを目的とします。この記事を読み終えると、LightGBMでのモデル作成ができるようになります。
環境
- Python 3.8.8
- pandas 1.2.4
- numpy: 1.20.1
- matplotlib: 3.3.4
LightGBMとは
LightGBMは、「メモリ効率が良く学習スピードが速い」「高い精度が期待できる」という特徴があります。過学習しやすい、という特徴もあるものの、テーブルデータなどでは1’st Choiceとしている方も多いようです。「私も是非、使ってみたい」と思い、いくつか公開してくださっているコードを確認していったのですが、すぐに行き詰ってしまいました。
そもそもLightGBMには2種類のAPIがあることも知らずに、複数のコードを読んでいたため、先ほどのコードではtrainで学習させていただのに、今度のはfitで学習させている???と混乱していました。まず、ここを整理して考えると理解しやすいかと思います。私もこの違いを整理して、あらためてコードを確認していくことで、理解することができました。
早速見ていきましょう。
2種類のAPI
既に記載したように、LightGBMには2種類のAPIが用意されています。
https://lightgbm.readthedocs.io/en/latest/Python-API.html
- Training API
- Scikit-learn API
Scikit-learn APIはTraining APIのラッパーライブラリでscikit-learnでモデル作成するときのような使い勝手でLightGBMモデルを構築することができます。(ちなみにTraining APIでは学習時にtrainを使い、Scikit-learn APIでは学習時にfitを使います。)
まずはTrainig APIの方から見ていきましょう。
Training APIの使い方の概要
まずは使い方の概要をまとめておきましょう。大まかに以下の3つのステップで進めます。
データの準備する工程で「Datasetオブジェクト」を作成するところが、これまでScikit-learnでおこなってきたデータの準備とは異なります。ただ、難しくはないので順にみていくことにしましょう。
事前準備
今回はデータ分析の学習を進める中で必ず遭遇する「Titanic」のデータセットを使うことにしましょう。このデータセットはKaggleで提供されています。「Titanic – Machine Learning from Disaster」というコンペの「Data」タブから入手することができます。
ここではtrain.csvを使います。
#ライブラリのインポート
import numpy as np
import pandas as pd
import os
import matplotlib
import seaborn as sns
# モデリング
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
# ディレクトリの設定
INPUT_DIR = './Input'
OUTPUT_DIR = './Output'
os.makedirs(OUTPUT_DIR, exist_ok=True)
# データの読み込み
df_train = pd.read_csv(f'{INPUT_DIR}/train.csv')
df_train.head(3)
今回はデータの前処理や特徴量生成の工程をすっ飛ばして、「Pclass」「Fare」「Age」の列のみを使うことにしましょう。
# 説明変数と目的変数
feature_names = ['Pclass', 'Fare']
X, y= df_train[feature_names], df_train[['Survived']]
print('説明変数と目的変数のデータの形状')
print(X.shape, y.shape)
# train用とvalidation用のデータセットに分割
X_train, X_validation, y_train, y_validation = train_test_split(X, y, test_size=0.2,random_state=0)
print('train/validation分割後の説明変数と目的変数のデータの形状')
print(X_train.shape, y_train.shape, X_validation.shape, y_validation.shape)
Training APIを使ってLight GBMのモデルを作る
Datasetオブジェクトを作る
Training APIでLight GBMのモデルを作る際には、事前にDatasetオブジェクトを作成する必要があります。次の書式となります。
dataには説明変数、labelには目的変数、feature_nameには説明変数の名前をリストで指定します。このlgb.Dataset()の返り値はDatasetオブジェクトなります。
この返り値のDatasetオブジェクトに対してdata属性で説明変数に、label属性で正解ラベル(目的変数)にアクセスすることができます。このDatasetオブジェクトをtrainデータ用とvalidationデータ用の2つ作る必要があります。
# Datasetオブジェクトの作成
train_data = lgb.Dataset(data=X_train,label=y_train,feature_name=feature_names)
validation_data = lgb.Dataset(data=X_validation,label=y_validation,feature_name=feature_names)
print(train_data.data)
print(train_data.label)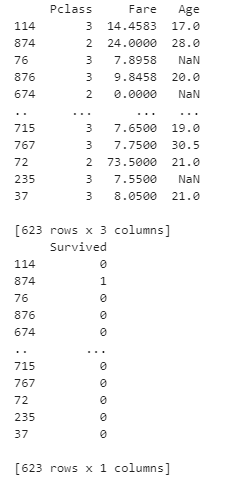
ハイパーパラメータの準備
はじめはあまり気にせずに、動くものを作る、ことに専念することにして、わからないければ数字の設定しているものは以下を設定してしまいましょう。ただ、objectiveやmetricに関しては課題にあったものを選択する必要があります。
objectiveでは、「regression」(回帰)「binary」(二値分類)「multiclass」(多クラス分類)、metricでは、評価関数で「mae」「mse」「rmse」(回帰問題)、「binary-logloss」「binary-error」「auc」(二値分類)「multi-logloss」「multi-error」(多クラス分類)を設定することができます。
今回は以下のように設定しました。
params = {
'boosting_type':'gbdt',
'objective':'binary',
'metric':'auc',
'num_leaves':16,
'learning_rate':0.1,
'n_estimators':100000,
'random_state':0
}モデルの構築
いよいよモデルの構築です。Training APIでは学習はtrain()を使います。params引数でハイパーパラメータを渡します。続いて、train_setにtrain用のDatasetオブジェクトを渡します。valid_setsにはtrain用・検証用のDatasetオブジェクトをリストで渡します。
残りは学習に関連するパラメータの設定です。
- num_boost_round
1つの学習器を作る作業を何度繰り返すか(エポック数といいます)を表します。 - early_stopping_rounds
評価指標が改善しなくなったら学習を止めるための仕組みです。指定した回数連続で指標が改善しなかった場合は学習を停止します。
※ただ現在は推奨されていないようです。詳しくは以下の記事をご覧下さい。

実際にやってみましょう。
# モデルの構築・学習
bst = lgb.train(
params = params,
train_set = train_data,
valid_sets=[train_data, validation_data],
num_boost_round=100,
early_stopping_rounds=100)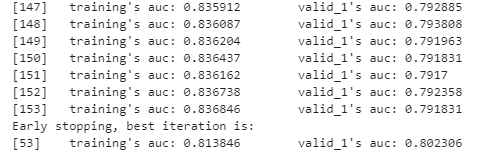
上記のように実行ログとともに学習が進行します。私の環境では53回目の学習以降、100回の学習を重ねても検証用データセットの評価指標の改善が見られたなかったため、学習が停止となっています。
予測と評価
モデルの学習が完了したので予測をしましょう。これは学習済みのモデルに対してpredict()とするだけです。以下の書式となります。
num_iteraionには学習時に最も汎化誤差が小さかったイテレーション数である、model.best_iterationを指定します。学習データ・検証データでそれぞれaccuracy(正解率)を算出してみましょう。
# モデルを使って訓練データ・検証データを予測
y_tr_pred = bst.predict(X_train, num_iteration=bst.best_iteration)
y_va_pred = bst.predict(X_validation, num_iteration=bst.best_iteration)
y_tr_pred = y_tr_pred.round(0)
y_va_pred = y_va_pred.round(0)
# 訓練データ・検証データのaccracyでの評価
accuracy_tr = accuracy_score(y_tr_pred,y_train)
accuracy_va = accuracy_score(y_va_pred,y_validation)
print(f'[accuracy] 訓練データ:{accuracy_tr:.5f} 検証データ:{accuracy_va:.5f}')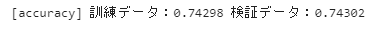
訓練データの予測値をy_tr_pred、検証データの予測値をy_va_predとしています。5,6行目は四捨五入で0or1に丸めています。最後に実際の訓練データの正解y_trainと検証データの正解y_validationをaccuracy_scoreにいれて正解率を計算しています。正解率は高くないものの、訓練データと検証データの正解率の差が小さい汎化誤差の小さいモデルとなっています。
最後に混同行列も見ておきましょう。
▶ 混同行列の基本を確認したい場合は以下の投稿をご覧ください。

既に検証データでの予測値y_va_predがあるので次のようにできます。
# 混同行列
cm = confusion_matrix(y_validation,y_va_pred)
cm_matrix = pd.DataFrame(data=cm,columns=['Actual Positive:1','Actual Negative:0'],
index=['Predict Positive:1','Predict Negative:0'])
# ヒートマップで描画
heatmap = sns.heatmap(cm_matrix, annot=True, fmt='d',cmap='coolwarm')
# heatmap.set_title('混同行列',fontsize=20)
heatmap.set_xticks([0.5,1.5])
heatmap.set_xlabel('事実',fontsize=20)
heatmap.set_xticklabels(['Positive:1','Negative:0'],fontsize=15)
heatmap.set_ylabel('予測',fontsize=20)
heatmap.set_yticks([0.5,1.5])
heatmap.set_yticklabels(['Positive:1','Negative:0'],fontsize=15)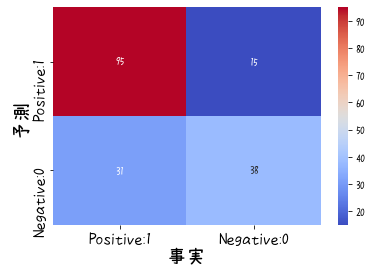
まとめ
いかがでしょうか?今回はLightGBMのモデル構築をみてきました。そもそも2種類のAPI、「Training API」と「Scikit-learn API」があって少し書き方が異なる部分があります。今回は「Training API」によるモデル構築のみをおこないました。
LightGBMでは、データをDatasetオブジェクトで扱います。この辺が慣れていないと、あれ?となるかもしれませんね。今回は数値の2変数のみだったので扱いませんでしたが、カテゴリ変数を扱う場合のやり方にも少し注意する点があります。ただ、はじめはLightGBMでのモデル構築のハードルを下げたかったので、今後、モデルの改善をやるときに扱うことにします。
コメント