
Pythonによる業務効率化の記事をこの他にも公開しています。



はじめに
今回は住所データから都道府県を抽出してみます。これまでに扱った、「正規表現」を使うことで、住所データから都道府県のみを抽出することができます。データは、オープンデータとして公開されている、日本全国の住所マスターデータを使ってみましょう。
サンプルデータ
Geolonia(ジオロニア)と不動産テック協会が全国の町丁目レベル(189,540件)の住所データをオープンデータとして公開してくれています。これを使ってみましょう。以下のページの「ダウンロード」からデータを取得しましょう。

# ライブラリのインポート
import pandas as pd
# ダウンロードしたデータの読み込み
address=pd.read_csv('C:/blog/address_list.csv')
# データの確認
address.sample(5)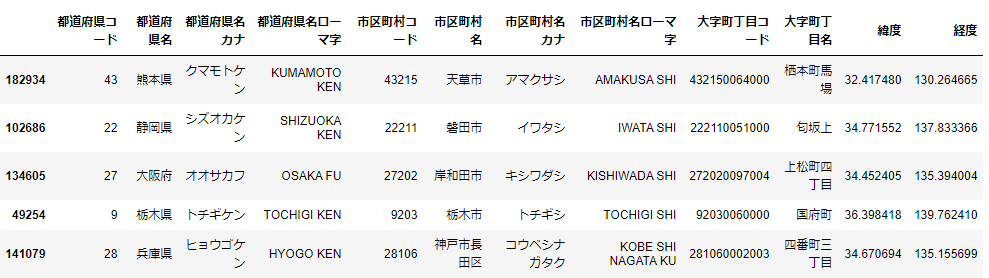
データの確認では、address.head()でよいのですが、北海道のデータが並んでしまって面白くないので、ランダムに取り出しています。このデータでは、既に「都道府県」が抽出されているので、都道府県、市区町村、大字町丁目名をつなげましょう。(本末転倒ですが・・・)
つなげたデータを「住所」というカラムとしています。
# 住所データの作成
address_list=address[['都道府県コード','都道府県名','市区町村名','大字町丁目名']]
address_list['住所']=address_list['都道府県名']+address_list['市区町村名']+address_list['大字町丁目名']
address_list=address_list[['住所']]
address_list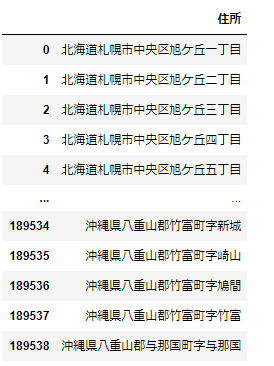
このようなデータが与えられたとして、都道府県を抽出することを考えます。
都道府県を抽出する
Pytonで正規表現を扱うには、「re」ライブラリを使うのでしたね。まず、最初にインポートしておきましょう。正規表現のメタ文字と特殊シーケンスについては、こちらの記事を参考にしてください。
都道府県を抽出することを考える場合、「都」については「東京都」のみ、「道」については「北海道」のみ、「府」については「大阪府」と「京都府」があって、「県」については、複数の県があります。「県」の前に、2 or 3文字と決まっています。このように抽出したいデータの条件を整理していけば、あとは正規表現でどのようにかくかを考えるだけですね。
# ライブラリのインポート
import re
# 都道府県の抽出する正規表現パターンをつくる
pattern = '東京都|北海道|(京都|大阪)府|.{2,3}県'
# 都道府県を抽出する
address_list['都道府県']=address_list['住所'].apply(lambda x:re.match(pattern,x).group())
address_list
match()では、返り値はマッチオブジェクトとなることに注意してください。マッチした文字列が欲しいときには、group()メソッドで取り出します。無事、都道府県を抽出することができてそうですね。確かめてみましょう。
address_list['都道府県'].unique()
ちゃんとできてますね!
まとめ
いかがでしたか?一見、難しそうでも、一つずつ整理していけば問題ないですね。文字列を取り出したくなったときには、是非思い出してください。
コメント