
正規表現の基礎を整理したその他の記事も是非ご覧下さい。


はじめに
前回に引き続き、正規表現を扱います。前回はメタ文字と特殊シーケンスを整理して、reモジュールでの利用方法を確認しました。今回は、実際にデータを処理するときによく出会う問題に対して、その処理をみていきましょう。
前処理での利用例
データを分析しようとすると、まずは、条件に合致したデータの抽出が必要なことがあります。既にcolumnsが整理されていて、columnsの値を指定するだけなら簡単ですが、実際にはそんなにきれいなデータばかりではありません。そんなときは、columnsの中にある値に条件を指定してデータを抽出する場面もあります。実際に見ていきましょう。
命名ルールのあるコードの処理
あるWebサービスでは正常に処理できたものに10桁の数字を割り当てているのですが、正常に処理できなかったものは9から始まる10桁の数字を割り当てる、というようなことをしています。あるいは、会員は先頭文字がAで、非会員は先頭文字がZというような場合もあるかもしれません。このような場合の抽出をみてみましょう。
# データの作成
df_sample=pd.DataFrame({'No':[0,1,2,3,4,5,6],
'処理コード':['1000345321','1987635434','1149876432','9045873621','9765487658','1039587643','9145834321'],
'アセット名':['xxxx20200623','yyyy20200625','xxxx20200623','aaaaa20200623','xxxx20200624','xxxx20200623','xxxx20200627']})
df_sample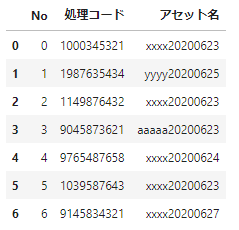
ここから処理コードが9で始まるものを除く、という処理をしてみましょう。この程度なら、正規表現を使わなくても次のように処理できます。
df_sample.query('not 処理コード.str.startswith("9")',engine='python')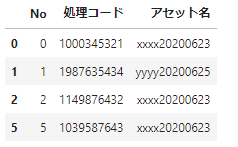
これを正規表現で次のように書くことができます。
df_sample.query("not 処理コード.str.contains('^9',regex=True)",engine='python')この程度なら正規表現を使う必要もないかもしれませんが、簡単な例で慣れておくと、複雑な条件のときも正規表現によるデータの抽出をすることができるようになります。たとえば、9から始まるではなく、7または8または9で始まるものを抽出するときは、正規表現だと次のように簡単に書けます。
df_sample.query("not 処理コード.str.contains('^[7-9]',regex=True)",engine='python')次に、末尾を指定するケースを見てみましょう。たとえば、末尾に必ずyymmddをつけているようなケースで、特定の日付のものを抽出するときなどです。たとえば、末尾が20200623のものを取り出してみましょう。これも正規表現を使わなくてもできます。
df_sample.query('アセット名.str.endswith("20200623")',engine='python')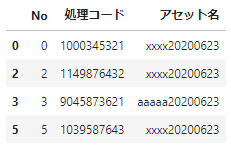
df_sample.query("アセット名.str.contains('20200623$',regex=True)",engine='python')末尾が20200623だけでなく、20200624,20200625の場合も取り出すときはどうしたらよいでしょう。次のようにすることで簡単に取り出すことができます。
df_sample.query("アセット名.str.contains('[20200623|20200624|20200625]$',regex=True)",engine='python')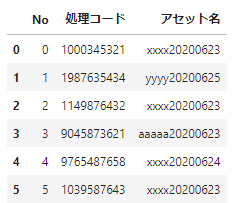
では、アセット名の先頭がxで始まり、末尾が3で終わるものを取り出すにはどうしたらよいでしょうか?これも簡単ですね。
df_sample.query('アセット名.str.contains("^x.*3$",regex=True)',engine='python')
まとめ
いかがでしたか?使い方次第で強力な武器になることが何となく伝われば、幸いです。複雑な組み合わせの条件は、正規表現を使うことで簡単に表現できる場合があります。よく復習しておきましょう。
コメント