
▶ 単純なデータのサンプリングの話は以下の記事をご覧ください。

はじめに
前回は、データの一部を取り出すサンプリングについて扱いました。今回は、特に、不均衡データの処理について学びます。不均衡データの処理には、「アンダーサンプリング」と「オーバーサンプリング」がありますが、今回は「アンダーサンプリング」についてご紹介します。
今回の投稿を作成するにあたっては、以下のブログを参考にさせてもらいました。
サンプルデータの作成
以下のようにsklearnのmake_classificationを利用すると、疑似的な不均衡データを簡単に(?)作成できます。今回、ご紹介したいのは「アンダーサンプリング」の部分なので、サンプルデータの作成の詳細については、ご紹介したブログを参照してください。
# ライブラリの読み込み
from sklearn.datasets import make_classification
# サンプルデータの作成
sample_data = make_classification(
n_samples = 100000, n_features = 3, n_classes = 2,
n_informative=1,
n_redundant=0,
n_repeated=0,
n_clusters_per_class=1,
weights = [0.9999, 0.0001],
random_state = 42)
sample_data
このように、make_classificationでは、2つの返り値がタプルで返されます。1つめのsample_data[0]をX、sample_data[1]をyと考えるとわかりやすいでしょう。これをデータフレームに変換しておきましょう。
# データフレームに変換する
df=pd.DataFrame(sample_data[0],columns=['columns1','columns2','columns3'])
df['target']=sample_data[1]
df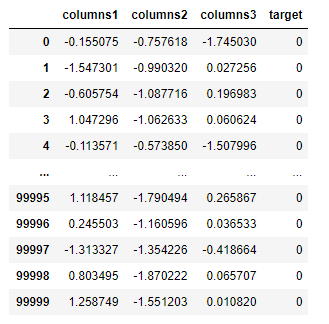
不均衡のままモデルを作成すると・・
ここでは、不均衡データを処理せずにそのまま扱った場合に起こる「問題」のわかりやすい例を紹介します。不均衡データのまま、ロジスティック回帰モデルを作成してみましょう。
# ライブラリのインポート
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
# 学習用と検証用に分割
X = df.iloc[:, 0:3]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# モデル構築
lr_model = LogisticRegression()
lr_model.fit(X_train, y_train)
# 予測値算出
y_pred = lr_model.predict(X_test)正解率を求めてみましょう。
# スコアの計算
raw_score=accuracy_score(y_test,y_pred)
print(raw_score)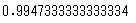
正解率99.4%。一見、正解率の高いよいモデルに見えますが、これは不均衡データが引き起こす典型的な例となります。このモデルの混同行列をみてみましょう。
# 混同行列
tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()
(tn, fp, fn, tp)
# 出力
(29997, 0, 3, 0)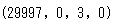
混同行列について、少しおさらいしておきましょう。
TN(True Negative):判別対象外のものを正しく判別できた数「真陰性」
FP(False Positive):判別対象外のものを誤って判別してしまった数「偽陽性」
FN(False Negative):判別したいものを誤って判別できなかった数「偽陰性」
TP(True Positive):判別したいものを正しく判別できた数「真陽性」
これに照らし合わせてみると、TNが29997,FNが3であり、単にすべてをNegativeと予想したにすぎません。不均衡(ほとんどがNegative)データであるため、このように大多数の方を一択で予想するだけで、正解率(Accuracy)は高い数字となります。しかし、実際には使えないモデルとなってしまいます。
このような事態を避けるために、正解率(Accuracy)だけで評価するのではなく、次のような指標を合わせて用います。
適合率(precision):陽性と予測されたデータのうち、実際に陽性であるものの割合
再現率(recall):実際の陽性のデータのうち、陽性と予測できたものの割合
実際に計算してみましょう。
# 適合率・再現率の算出
print('precision : %.4f'%(tp / (tp + fp)))
print('recall : %.4f'%(tp / (tp + fn)))
このように、適合率(precision)は計算できない、再現率(recall)は0、という散々たる結果となりました。
このような事態を避けるために、不均衡データでは、データの偏りを少し緩和することを考えます。以降では、アンダーサンプリングによる方法を見ていきましょう。
アンダーサンプリングをしてモデルを作成する
アンダーサンプリングの処理には、imbalanced-learnというライブラリを活用します。まずは、pipでインストールしておきましょう。
pip install -U imbalanced-learn これで準備ができました。実際にアンダーサンプリングをしてみましょう。
# ライブラリのインポート
from imblearn.under_sampling import RandomUnderSampler
# サンプリング
rs=RandomUnderSampler(random_state=42)
df_sample,_=rs.fit_sample(df,df.target)
print()
print('*'*20)
print('<元のデータ>')
print('0の件数:%d'%len(df.query('target==0')))
print('1の件数:%d'%len(df.query('target==1')))
print('*'*20)
print('<アンダーサンプリング後のデータ>')
print('0の件数:%d'%len(df_sample.query('target==0')))
print('1の件数:%d'%len(df_sample.query('target==1')))

今回の例では、target(0 or 1)の数が完全に一致するようにしました。しかし、実際にはここまで大胆にデータのバランスを崩すと、いろいろな問題がありますん。実際にモデルをみてみましょう。
# 学習用と検証用に分割
X = df_sample.iloc[:, 0:3]
y = df_sample['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# モデル作成
mod = LogisticRegression()
mod.fit(X_train, y_train)
# 予測値算出
y_pred = mod.predict(X_test)
# Accuracyと混同行列
print('Confusion matrix(test):\n{}'.format(confusion_matrix(y_test, y_pred)))
print('Accuracy(test) : %.5f' %accuracy_score(y_test, y_pred))
# PrecisionとRecall
tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()
print('precision : %.4f'%(tp / (tp + fp)))
print('recall : %.4f'%(tp / (tp + fn)))
# 出力
precision : 0.0022
recall : 0.6667
このように適合率(precision)、再現率(recall)に改善はみられるものの、正解率(accuracy)は48.3%にまで落ち込んでしまいました。このように単純に数をそろえればよい、というものではなく、バランスが大切となります。
実際のモデル作成時には、少ないデータの割合を10%まで高める、オーバーサンプリングとアンダー散布リグを組み合わせて使う、などいろいろ試してみるとよいでしょう。
まとめ
今回はアンダーサンプリングを扱いました。オーバーサンプリングも、ほぼ同じ工程で実施することができます。今回は、不均衡データをもとにモデルを作る際に起こる問題と、単純にデータを均衡化するだけではうまくいかない、といったことを示しました。難しい内容ですが、よく復習しておきましょう。
▶ データ分析をする過程ではまだまだいろんな前処理があります。以下の記事もあわせて参考にしてください。



コメント