
正規表現の続編の記事もあります。


はじめに
今回は基本的な正規表現を整理して、少し慣れるようにしたいと思います。正規表現を完璧に扱えるようになる、というのはものすごく大変なんだと思います。ただ、データ分析の中でちょっとこんな加工ができたらなぁ、というときに使う程度ならそんなに敷居は高くありません。さっそく始めましょう。
正規表現とは
正規表現とは、文字列を1つのパターン化した文字列で表現する表記法です。
https://techacademy.jp/magazine/15635
正規表現を使用して、文字列をパターン化した文字列に置き換えることで、文字列の検索や置換え、そして自然言語処理と呼ばれる広義の意味でのAI技術の基礎的な処理を行うことができます。
正規表現において、パターン化した文字列のことをメタ文字と言います。 まずはこのメタ文字から見ていきましょう。
メタ文字
これはWebを検索すると、まとめてあるものをすぐに見つけることができるでしょう。ここでもよく使うものを一覧にして掲載しておきます。
| メタ文字 | 説明 | 指定例 | 合致する |
| . | 任意の一文字 | a.c | abc,acc,aac |
| ^ | 行の先頭 | ^abc | abcdef |
| $ | 行の末尾 | abc$ | defabc |
| * | 0回以上の繰り返し | ab* | a,ab,abb,abbb |
| + | 1回以上の繰り返し | ab+ | ab,abb,abbb |
| ? | 0回または1回 | ab? | a,ab |
| {m} | m回の繰り返し | a{3} | aaa |
| {m,n} | m~n回の繰り返し | a{2,4} | aa,aaa,aaaa |
| [★] | ★のどれか1文字 | [a-c] | a,b,c |
| ★|★ | ★のどれか | a|b | a,b |
1列目にメタ文字、2列目にその意味を掲載しています。3列目は表記例で、4列目に3列目で表記した場合に合致する文字列を掲載しています。
特殊シーケンス
よく利用される正規表現のパターンは、特殊シーケンスと呼ばれます。 これも整理しておきましょう。
| 特殊シーケンス | 説明 | 同じ意味の正規表現 |
| \d | 任意の数字 | [0-9] |
| \D | 任意の数字以外 | [^0-9] |
| \s | 任意の空白文字 | [\t\n\r\f\v] |
| \S | 任意の空白文字以外 | [^\t\n\r\f\v] |
| \w | 任意の英数字・アンダースコア | [a-zA-Z0-9_] |
| \W | 任意の英数字・アンダースコア以外 | [^a-zA-Z0-9_] |
| \A | 文字列の先頭 | ^ |
| \Z | 文字列の末尾 | $ |
正規表現モジュールre
では、さっそく使ってみましょう。pythonでは正規表現を扱うモジュール「re」があります。まずはこれをインポートします。
# ライブラリのインポート
import re
# テキストの準備
sentence = 'aaa abc aac abb abab 123 112 111'reモジュールでよく使うメソッドを整理しておきましょう。
match():文字列の先頭がマッチするかをチェック・抽出する
search():先頭に限らずマッチするかチェック・抽出する
findall():マッチする部分すべてをリストで取得する
これを押さえておけば、使い方は簡単です。「re.メソッド(どんなパターン?, どこに適用する?)」という書き方をします。既に適用したい文字列は作っているので、正規表現のパターンを入れておく変数patternを定義して、実際にやってみましょう。
pattern = 'ab.'
results = re.findall(pattern, sentence)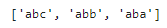
findallはマッチするパターンすべてを抽出するため、abの後に1文字のものをすべて抽出します。match(), search()も見ておきましょう。
sentence='aaa abc aac abb abab 123 112 111'
pattern = 'a..'re.match(pattern,sentence)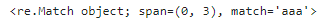
先頭がマッチしたので、それが抽出されてますね。次にsearch()メソッドです。
re.search(pattern,sentence)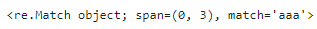
これも先頭がマッチするので、今回はmatch()メソッドの同じ結果となります。但し、1つしか抽出されません。
re.findall(pattern,sentence)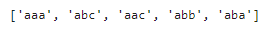
findall()メソッドでみてみると、実際には複数の文字列がマッチしますね。これらは用途によって使い分けるようにしましょう。
正規表現のパターンを変えてもう一つ例を見ておきましょう。
sentence='aaa abc aac abb abab 123 112 111'
pattern = 'ab.'re.match(pattern,sentence)これは何も結果を返しません。match()は文字列の先頭がマッチするかをチェックするメソッドで、今回は「ab.」ではマッチしませんね。一方、search()は先頭に限らずチェックしてくれます。
re.search(pattern,sentence)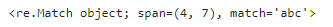
2つ目の文字列がヒットします。但し、search()の場合は、マッチした時点でそれ以降のチェックは中断します。始めにマッチしたものだけを抽出することに注意しましょう。
re.findall(pattern,sentence)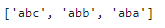
まとめ
さて、いかがでしたでしょうか?すごく簡単な例しか示しておりませんが、なんとなく、とっつきにく、という部分が取り除けていれば幸いです。よく復習しましょう。
コメント