
この記事はこんな方におススメです
はじめに
統計学を学んだことがない方を対象に基本から解説しています。今回は、データを入手したらまず最初におこなう「分布」の確認についてです。分布を確認するにあたり、連続変数の場合とカテゴリ変数の場合に分けて、Pythonによる可視化の方法を基本から解説します。
分布
データを入手したらまずは分布を確認しましょう。データがどのように分布しているかを確認しなくては、平均値のような代表値を算出しても意味があるかわかりません。変数が多すぎてすべてを可視化して確認できない場合もあるかもしれませんが、できる限り可視化して確認するようにしましょう。
まずはライブラリのインポートとサンプルデータの作成をおこないましょう。
# ライブラリのインポート
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
%matplotlib inline
# サンプルデータの作成
money=[300,500,1000,1500,2000]
moneys=random.choices(money,k=12)
spend=[75,90,120,130,170,199,283]
spends=random.choices(spend,k=12)
animals=pd.DataFrame({'どうぶつのなまえ':['らくだ','ねこ','いぬ','きりん','ぞう','ぶた','あらいぐま','さる','ぺんぎん','くじら','いるか','しまうま'],
'せいべつ':['男','女','女','女','男','女','男','女','女','女','男','男'],
'とし':[8,3,6,9,10,21,2,3,7,2,21,34],
'おこづかい':moneys,
'つかったおかね':spends})連続変数の分布
連続変数の分布を可視化するにはヒストグラムを使います。分布とは、どの値にどのくらいのデータがあるか、です。「どの値」の部分を「区間」であらわします。これを「ビン」といいます。区間の幅やビン数を直接指定することもできますが、今回は、まず可視化する方法だけとしましょう。ヒストグラムはseabornのdisplot()で描くことができます。
# ヒストグラムのプロット
sns.displot(animals['とし'],kde=False)
plt.title('動物たちの年齢',fontsize=18)
plt.grid()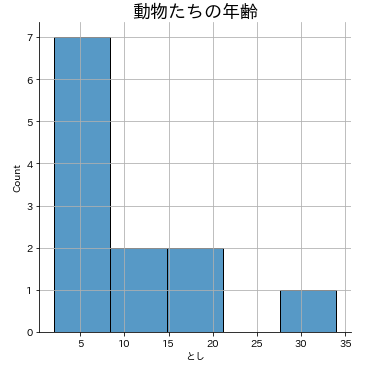
▶ ヒストグラムの描画に関してはこちらの記事も参考にしてください。

Python初心者向け:データの可視化の方法を基本からまとめました
データ分析の初心者にもわかるように、データの可視化の方法を基本から丁寧に解説します。この記事を読むことで、グラフを描く基本的な方法が理解でき、多くのグラフを描くことができ量になります。matplotlibとseabornライブラリを使った可視化を解説します。
happy-analysis.com
2021.11.19

Python:可視化(ヒストグラム)
はじめにヒストグラムはデータの分布状況を可視化するときに使うグラフとなります。データを見るだけではなかなか把握しにくい、ばらつきを可視化することができます。ヒストグラムは横軸に階級、縦軸に度数をとり、各階級の度数を長方形の柱で表します。ここ...
happy-analysis.com
2021.11.19
カテゴリ変数の分布
次にカテゴリ変数の場合です。カテゴリ変数の場合は棒グラフを使います。これはseabornのcatplot()で描きます。引数kindに「count」を指定すればOKです。
# 棒グラフのプロット
sns.catplot(x='せいべつ',data=animals,kind='count')
plt.title('どうぶつたちのせいべつ')
plt.grid()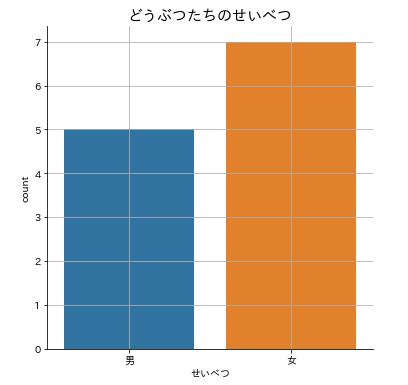
▶ catplot()に関しては以下の記事でも紹介しています。こちらも是非ご覧ください。

まとめ
今回は分布について、連続変数とカテゴリ変数にわけて解説しました。分布の可視化が第一歩なので、是非身につけておきましょう。
▶ 統計学の初学者向けの記事を書いています。以下の投稿もどうぞ。

コメント