
▶ 正規表現の基本については以下の投稿をご覧ください。


はじめに
今回は再び正規表現を扱います。正規表現って奥が深いですね。基本を整理したので、実データに向き合ってみたら、早速つまづきました。友人の助けを経て無事処理できたので備忘録で記録を残しておきます。
サンプルデータの作成
小学校の図書室に寄せられたアンケートデータということにしましょう。以下のようなデータを作ってください。
# ライブラリのインポート
import pandas as pd
import re
# アンケートデータの作成
animals=['らくだ','ねこ','らいおん','しまうま','きりん']
text_data=[
'『ずっこけ3人組大冒険』と『15少年漂流記』が面白かったです。',
'「Python実践データ分析」で基本的なデータ分析の流れをつかむことができました。',
'特にありません。',
'いつもありがとうございます。「ドラえもん」「スラムダンク」「キン肉マン」「20世紀少年」を置いてほしいです。漫画ですが、お願いします。',
'「日本の歴史」と『世界の歴史』はいつも貸し出し中なので増やしてほしい。'
]
df_sample=pd.DataFrame({'記入者':animals,'アンケート':text_data})
df_sample
やりたいこと
今回は架空の話ですが、アンケートの中から「」や『』で囲まれた本の名前を抜き出すことを考えましょう。
括弧で囲まれた部分を抽出する正規表現
括弧付きで抽出
結果からいうと、
『.*?』|「.*?」
という正規表現で抽出することができます。これって不思議ですね。.(ドット)は任意の一文字、*(アスタリスク)は0回以上の繰り返し、?(クエスチョンマーク)は0回または1回を表すのでした。この知識だけだと、さっぱりわかりません。
実は、*?のように*(アスタリスク)と?(クエスチョンマーク)を組み合わせると、「最短マッチ」になるそうです。一方で、.*だけでは、「最長マッチ」なので、行の一番最後に見つかる閉じ括弧までをマッチしてしまいます。
言葉だけで説明してもよくわらないですね。具体例でみてみましょう。
# 正規表現のパターンを定義
pattern_greedy = '『.*』|「.*」'
pattern_non_greedy = '『.*?』|「.*?」'
p1_books=[]
p2_books=[]
for text in df_sample['アンケート']:
tmp1=re.findall(pattern_greedy,text)
tmp2=re.findall(pattern_non_greedy,text)
p1_books.append(tmp1)
p2_books.append(tmp2)pattern_greedyが最長マッチ、pattern_non_greedyが最短マッチです。結果を見てみましょう。
p1_books
こちらは最長マッチの例です。1つめのデータからうまくいっていません。実は、『ずっこけ3人組大冒険』だけでデータを抽出したいのですが、一番最後の閉じ括弧でマッチしています。4つ目のデータも一見、データが取得できているようですが、これも最長マッチしているため、「ドラえもん」「スラムダンク」「キン肉マン」「20世紀少年」が1つの要素になってしまっています。
一方で、最短マッチの方はどうでしょうか?
p2_books
こちらはうまくいっているようです。1つ目や4つ目のデータのように括弧を含む文字列が複数含まれていても、別々に抽出できています。また、5つ目のように括弧と二重括弧が混在したケースでもうまく処理できてますね。
括弧の中身だけを抽出
この場合は、少し複雑になりますが次のようになります。
pattern_non_greedy_2 = '(?<=『).*?(?=』)|(?<=「).*?(?=」)'説明のために二重括弧の部分だけを抜き出して考えてみましょう。
(?<=『).*?(?=』)
これを分解すると、
(?<=『)
.*?
(?=】)
となります。これは「肯定先読み」「肯定戻り読み」の表現を用いています。
- 肯定先読み
(?=正規表現) - 肯定戻り読み
(?<=正規表現)
この先読み・戻り読みの表現では、( )の中でマッチした文字列はキャプチャしません。そのため、『 , 』を除去して抽出することができます。
pattern_non_greedy_2 = '(?<=『).*?(?=』)|(?<=「).*?(?=」)'
p3_books=[]
for text in df_sample['アンケート']:
tmp3=re.findall(pattern_non_greedy_2,text)
p3_books.append(tmp3)
p3_books
最後のもう少しデータを処理しておきましょう。まずはアンケートから本を抽出できたのでこれをくっつけてみましょう。
df_connect=pd.concat([df_sample,pd.DataFrame({'本の名前':p3_books})],axis=1)
df_connect

次に、「本の名前」の列に複数の本が入っているとわかりにくいので、誰が求めているかわかる形で、本のデータを縦に並べることにしましょう。
voters=[]
books=[]
for animal,book in zip(df_connect['記入者'],df_connect['本の名前']):
if len(book)==0:
voters.append(animal)
books.append(book)
elif len(book)==1:
voters.append(animal)
books.append(book[0])
else:
for i in book:
voters.append(animal)
books.append(i)
df_result=pd.DataFrame({'投票者':voters,'本の名前':books})
df_result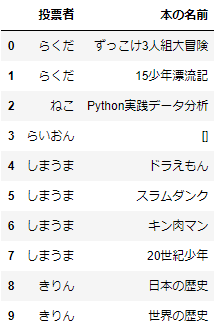
これで誰がどの本を求めているかがわかるようになりましたね。
まとめ
いかがでしたか?正規表現は奥が深いですね。一度に学ぼうとせずに、必要に迫られた時に、少しずつ調べながらやっていきたいと思います。
この他にも正規表現を使った処理の事例があります。

コメント