
▶ sklearnを用いた正規化についてはこちらの記事で扱っています。

はじめに
今回は機械学習のフレームワークであるscikit-learnの中にある、前処理を扱う機能についてご紹介します。scikit-learnの中には前処理をおこなうためのpreprocessingというライブラリがあります。たくさんのメソッドがありますが、今回はこの中のscaleメソッドを扱います。
preprocessingにあるメソッド
さっそく見ていきましょう。まずは必要なライブラリをインポートしましょう。
# ライブラリのインポート
import pandas as pd
import seaborn as sns
import numpy as np
from sklearn import preprocessingこれで準備は完了です。ところで、フレームワークとライブラリという用語はどのように使い分けてるか気になりませんでした?以下が参考になりました。

sklearnというフレームワークからpreprocessingというライブラリをインポートしています。まずは、preprocessingにどのようなメソッドがあるかをみてみましょう。
np.array(dir(preprocessing))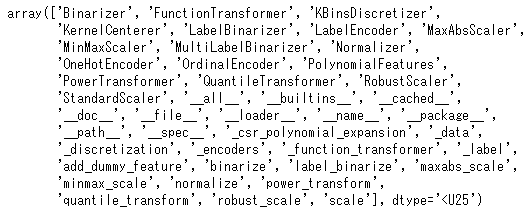
dir(ライブラリ名)でそのライブラリの持つメソッドがリストで返されます。そのままリストでもよいのですが、見やすくするためにnumpyのarray形式で表示させています。たくさんのメソッドがありますね。この中で今回はscaleを見ていきましょう。
scaleメソッドについて
scaleメソッドは、標準化をするためのメソッドです。ここでは、標準化・正規化を次のように使い分けています。

つまり、 平均を0にし、標準偏差を1に設定する メソッドです。次のように使います。
# irisデータの読み込み
iris=sns.load_dataset('iris')
iris.head()
先頭列のsepal_lengthを標準化してみましょう。
iris['sepal_length_ss']=preprocessing.scale(iris['sepal_length'])たった1行、これだけでできます。念のため、確認しておきましょう。
print('標準化前の平均は%.2fです'%iris['sepal_length'].mean())
print('標準化前の標準偏差は%.2fです'%iris['sepal_length'].std())
print('*'*30)
print('標準化後の平均は%.2fです'%iris['sepal_length_ss'].mean())
print('標準化後の標準偏差は%.2fです'%iris['sepal_length_ss'].std())
ちゃんと標準化(平均0、標準偏差1)できてますね!
まとめ
標準化は一度、扱ったことがあるので、さらっと済ませました。今後は、proprecessingの他のメソッドも見ていくことにしましょう。
▶ この他にもsklearnを使った前処理をご紹介しています。

コメント