
はじめに
前回に引き続き、scikit-learnのpreprocessingライブラリのメソッドについてみていきましょう。今回は、add_dummy_featrureとbinarizeについてみていきます。add_dummy_featureはその名の通り、ダミー項目を作成します。binarizeは、二値化することができるメソッドです。
サンプルデータ
# ライブラリの読み込み
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn import preprocessing
sns.set_style('whitegrid')
%matplotlib inline
# irisデータの読み込み
iris=sns.load_dataset('iris')
iris.head()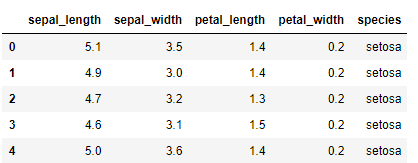
add_dummy_feature
ダミーの変数を追加することを考えましょう。次のようにすると、値がすべて1となるダミーの変数を追加することができます。
preprocessing.add_dummy_feature(iris[iris.columns[0:4]])
一度、内部的に値をfloat型に変換するため、float型に変換できないspeceisは除きました。このようにすると、先頭にダミーの配列を挿入することができました。いま、ダミー配列の値は、1となっていますが、これは任意の値にすることができます。valueという引数で値を指定してみましょう。
preprocessing.add_dummy_feature(iris[iris.columns[0:4]],value=0)
実は、valueの値は文字列を指定することもできます。但し、そのほかの列もすべて文字列に変換されてしまいます。
preprocessing.add_dummy_feature(iris[iris.columns[0:4]],value='X')
binarize
次に扱うのはbinarizeです。binarizeは、ある列に対して閾値を指定すると、その値より大きいか小さいかで2値に分類してくれるものです。
ここでは3を閾値にして、二値化してみましょう。
preprocessing.binarize(iris[iris.columns[0:4]],threshold=3)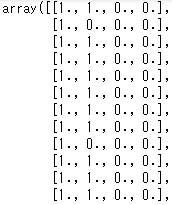
まとめ
いかがでしたか?どちらも他にもやり方があるので、必ずしもこのやり方を身に着ける必要はないかもしれませんが、いろんな方法を知っておくとよいですね。
▶ この他にもsklearnを用いた前処理を扱った記事があります。以下からどうぞ。

Python初心者向け:sklearnで標準化する方法を解説
Python初心者向けにsklearnライブラリを使った標準化の方法を基本から解説します。sklearnの前処理前処理を扱う機能(preprocessing)には、たくさんのメソッドがありますが、今回はこの中のscaleメソッドを用いた標準化を基本から解説します。
happy-analysis.com
2021.11.19

Python初心者向け:sklearnで正規化する方法を解説
Python初心者向けにsklearnライブラリを使った正規化の方法を基本から解説します。sklearnの前処理前処理を扱う機能(preprocessing)には、たくさんのメソッドがありますが、今回はこの中のscaleメソッドを用いた正規化を基本から解説します。
happy-analysis.com
2021.11.19
コメント