
▶ sklearnを用いた標準化についてはこちらの記事であつかっています。

はじめに
前回に引き続き、scikit-learnのpreprocessingのメソッドを見ていきます。前回は、標準化(平均0、分散1)するscaleメソッドを扱いました。今回は、正規化(最小値が0、最大値が1に)するminmax_scaleをみていきましょう。

minmax_scale
早速、やっていきましょう。まずはライブラリのインポートとデータの読み込みです。今回も、seabornで用意されているirisデータセットを使うことにしましょう。
# ライブラリの読み込み
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn import preprocessing
sns.set_style('whitegrid')
%matplotlib inline
# irisデータの読み込み
iris=sns.load_dataset('iris')
iris.head()
今回もはじめの列にあるsepal_lengthで試すことにしましょう。正規化したデータはsepal_length_mmとすることにしましょう。次の一行でもとめることができます。
iris['sepal_length_mm']=preprocessing.minmax_scale(iris['sepal_length'])さて、ちゃんとできているか検証をしてみましょう。
print('sepal_lengthの最小値は%.1fです。'%iris['sepal_length'].min())
print('sepal_lengthの最大値は%.1fです。'%iris['sepal_length'].max())
print('*'*30)
print('sepal_length_mmの最小値は%.1fです。'%iris['sepal_length_mm'].min())
print('sepal_length_mmの最大値は%.1fです。'%iris['sepal_length_mm'].max())
ちゃんとできているようですね。プロットでも確認しておきましょう。
plt.figure(figsize=(16,8))
plt.plot(iris.index,iris['sepal_length'],label='元のデータ')
plt.plot(iris.index,iris['sepal_length_mm'],label='正規化したデータ')
plt.legend(fontsize=15)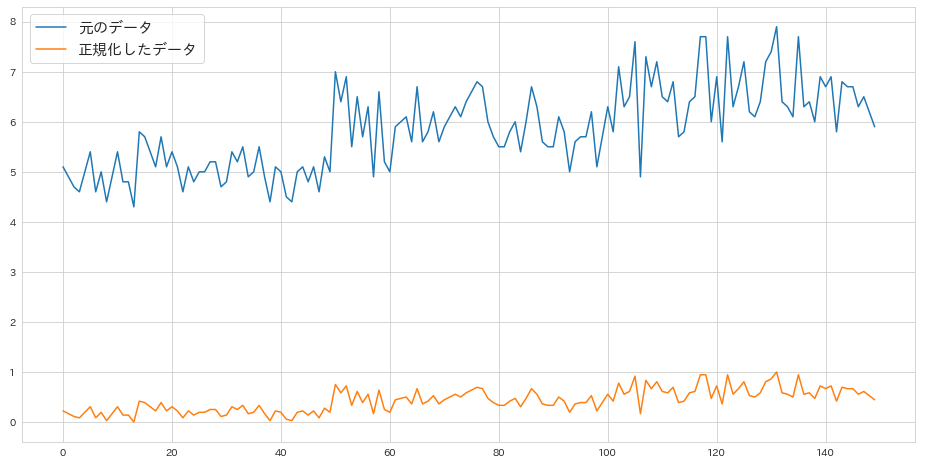
変換後は、ちゃんと最小値0、最大値1の間に収まっていますね。変換前データと変換後データの関係もみてみましょう。
plt.scatter(iris['sepal_length'],iris['sepal_length_mm'])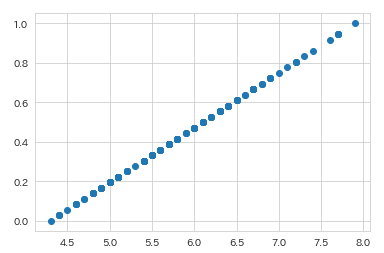
これで対応関係もわかりますね。各値が最小値0、最大値1になるように線形写像されています。
まとめ
いかがでしょうか?各列の値が異なるもの同士でも標準化や正規化をおこなって一緒に扱うことがあります。よく覚えておきましょう。
▶ この他にもsklearnを用いた前処理をご紹介しています。

コメント