
はじめに
今回は、データの前処理の1つである標準化/正規化/常用対数化を扱いましょう。実は、標準化/正規化については、この用語の明確な使い分けが定義されているわけではないようです。ここでは、各項目を説明する前に、このページ内での意味について記載しておきます。
標準化
「標準化」という言葉を調べてみました。こちらは、統計Webというサイトに次のような説明があります。
データを標準化すると、標準化したデータの平均は0に、分散(標準偏差も)は1になります。これにより、異なる項目のデータであってもその大小を比較できるようになります。
https://bellcurve.jp/statistics/course/19647.html
ここでは、平均を0、分散を1になるようなデータ加工と捉えておきましょう。次の式で「標準化」することができます。
(x - 平均) / 標準偏差xは各要素です。サンプルデータで実際に計算してみましょう。
# ライブラリの読み込み
import pandas as pd
import seaborn as sns
# irisデータの読み込み
iris=sns.load_dataset('iris')
# sepal_lengthの平均(mean)と標準偏差(std)
sepal_mean=iris.sepal_length.mean()
sepal_std=iris.sepal_length.std()
# 標準化
iris['sepal_length_standard']=(iris['sepal_length']-sepal_mean)/sepal_std
iris[['sepal_length','sepal_length_standard']]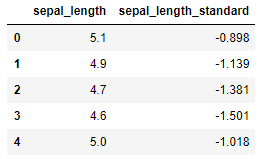
一応、検算をしてみましょう。
# 検算
# 検算
print('平均は%.2f'%iris.sepal_length_standard.mean())
print('分散は%.2f'%iris.sepal_length_standard.var())
標準化は、scikit-learnを利用する方法もあります。標準化は、preprocessingのscale()を使います。
# ライブラリの読み込み
from sklearn import preprocessing
# インスタンスの作成
iris['sepal_length_standard'] = preprocessing.scale(iris['sepal_length'])
iris[['sepal_length','sepal_length_standard']].head()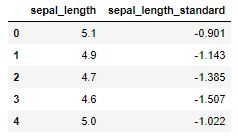
こちらも検算しておきましょう。(先ほどの結果と若干異なるので)
# 検算
print('平均は%.2f'%iris.sepal_length_standard.mean())
print('分散は%.2f'%iris.sepal_length_standard.var())
正規化
ここでは、「正規化」は、「最小値が0、最大値が1になるようにデータを加工(スケーリング)する」ということにしましょう。 次の式で「正規化」することができます。
(x - min) / (max - min)xは各要素、maxは最大値、minは最小値です。この定義に従って計算してみましょう。
# sepal_lengthの最大値(max)、最小値(min)
sepal_length_max=iris['sepal_length'].max()
sepal_length_min=iris['sepal_length'].min()
# 正規化
iris['min_max_sepal_length']=(iris['sepal_length']-sepal_length_min)/(sepal_length_max - sepal_length_min)
iris[['sepal_length','min_max_sepal_length']].head()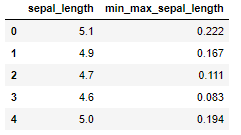
# 検算
print('最大値は%.2f'%iris['min_max_sepal_length'].max())
print('最小値は%.2f'%iris['min_max_sepal_length'].min())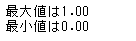
正規化も、scikit-learnを利用する方法があります。正規化は、preprocessingのminmax_scale()を使います。
# ライブラリの読み込み
from sklearn import preprocessing
# インスタンスの作成
iris['sepal_length_standard'] = preprocessing.minmax_scale(iris['sepal_length'])
iris[['sepal_length','sepal_length_standard']].head()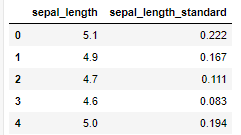
まとめ
いかがでしょうか?言葉の使い分けがあまりはっきりしないので、混乱することがありますが、毎回、何を意味しているのかを確認しながら導出すれば大きな混乱はありませんね。今回は定義に沿って地道に計算する方法と、scikit-learnライブラリを使う方法をご紹介しました。
▶ sklearnで標準化・正規化する方法を説明した個別記事もあります。


コメント