
はじめに
カテゴリデータを利用して機械学習を行う場合は、数値データに置き換える必要がります。但し、単純に数値に置き換えると大小関係を持ってしまうため、正しい学習ができません。ここではワンホットエンコーディングという1または0の値を持つカテゴリの有無を示す列を作成する方法を扱います。
カテゴリーデータを0と1だけで構成されているカテゴリーごとの列データに変換したものをダミー変数といいます。 ミー変数はPandasでも手軽に作ることができます。
サンプルデータの作成
何度か利用している動物たちのデータを使いましょう。
# サンプルデータの作成
df_sample=pd.DataFrame({
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ'],
'動物園':['上野動物園','旭山動物園','上野動物園','こどもどうぶつえん','ズーラシア','ズーラシア','旭山動物園'],
'年齢':[23,32,33,21,42,18,15]
})
df_sample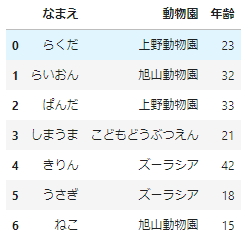
get_dummies()を使ってみる
get_dummies()の引数にデータフレームを適用してみましょう。
pd.get_dummies(df_sample)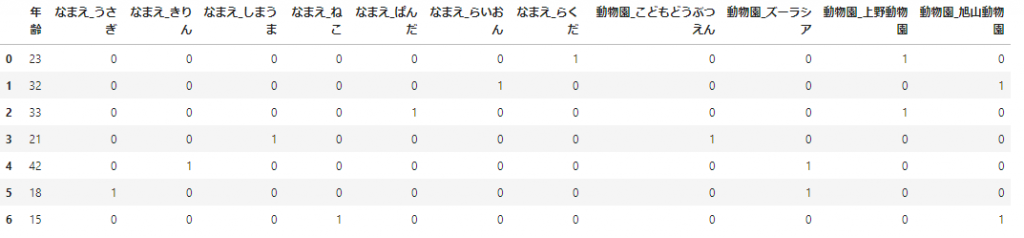
データ型がobjectあるいはcategoryである列がすべてダミー変数化されます。 このようにカテゴリ変数の各値のカラムが作られ、その値が見られたら1を返し、見られなかったら0を返しています。
少しわかりにくいので特定の列だけ指定してみましょう。2つ方法があります。1つはget_dummies()にシリーズを指定する方法です。
pd.get_dummies(df_sample['動物園'])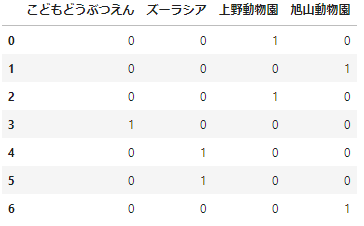
この方法では作成される列名は、もとのカテゴリ変数の値になります。もう一つの方法は、get_dummies(df,columns=[‘列名’]) とする方法です。
pd.get_dummies(df_sample,columns=['動物園'])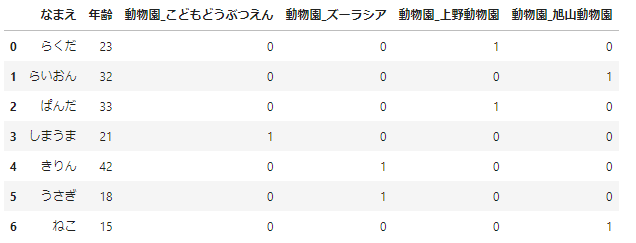
この方法では、作成される列名は、「元の列名_値」となります。prefixについては、次のように指定することができます。
pd.get_dummies(df_sample,columns=['動物園'],prefix='zoo')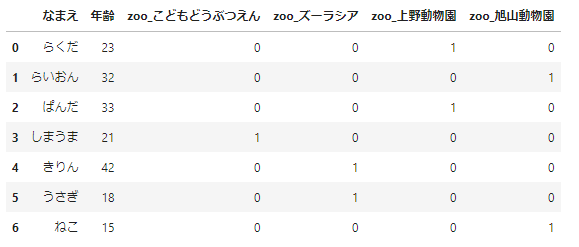
多重共線性を防ぐ
ダミー変数に拘束関係が働いてしまうと回帰分析がうまくできないといったケースが起こり得ます。これを多重共線性と呼びます。 たとえば、上記の例だと、「こどもどうぶつえん」「ズーラシア」「上野動物園」が0であると、「旭動物園」は1であることが自明となります。このような拘束関係があると、うまく回帰分析できないケースがあります。
そのため、1つクラスを削り情報量を最低限とすることで回帰がうまくいくようにすることができます。
pandasではdrop_first=Trueにすることで対処できます。
pd.get_dummies(df_sample,columns=['動物園'],prefix='zoo',drop_first=True)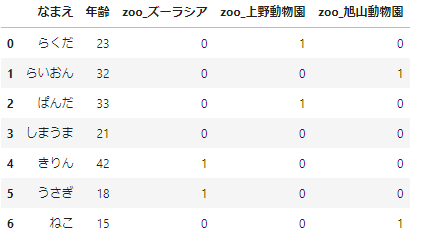
まとめ
いかがでしたか?カテゴリー変数を用いて機械学習するときには、必須の方法となるので、よく確認しておきましょう。
コメント