
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
はじめに
今回は再び正規表現を扱います。正規表現についてはこれまでにも扱ってきました。
▶ 正規表現に関してはメタ文字や特殊シーケンスを先にご確認ください。

今回はメタ文字や特殊シーケンスをおさらいしたうえで、実際にコードで試して確認していくことにします。そのため、前回はメソッドとして「match」「search」「findall」を紹介しましたが、今回は「search」のみを用いて、メタ文字・特殊シーケンスの確認に専念することにしましょう。
おさらい
「メタ文字」と「特殊シーケンス」に分けて整理しておきましょう。ここでは解説はせずにそれぞれ一覧を掲載することにします。ここではどんなものがあったかをざっとおさらいして、次の「確認」のセクションで実際にコードを書いて試してみましょう。
メタ文字のおさらい
| メタ文字 | 説明 | 指定例 | 合致する |
| . | 任意の一文字 | a.c | abc,acc,aac |
| ^ | 行の先頭 | ^abc | abcdef |
| $ | 行の末尾 | abc$ | defabc |
| * | 0回以上の繰り返し | ab* | a,ab,abb,abbb |
| + | 1回以上の繰り返し | ab+ | ab,abb,abbb |
| ? | 0回または1回 | ab? | a,ab |
| {m} | m回の繰り返し | a{3} | aaa |
| {m,n} | m~n回の繰り返し | a{2,4} | aa,aaa,aaaa |
| [★] | ★のどれか1文字 | [a-c] | a,b,c |
| ★|★ | ★のどれか | a|b | a,b |
特殊シーケンスのおさらい
| 特殊シーケンス | 説明 | 同じ意味の正規表現 |
| \d | 任意の数字 | [0-9] |
| \D | 任意の数字以外 | [^0-9] |
| \s | 任意の空白文字 | [\t\n\r\f\v] |
| \S | 任意の空白文字以外 | [^\t\n\r\f\v] |
| \w | 任意の英数字・アンダースコア | [a-zA-Z0-9_] |
| \W | 任意の英数字・アンダースコア以外 | [^a-zA-Z0-9_] |
| \A | 文字列の先頭 | ^ |
| \Z | 文字列の末尾 | $ |
確認
ではさっそく試していきましょう。正規表現を扱うモジュールreをインポートして、findall()メソッドを使って確認していきましょう。
findall()メソッドのDocstringをみてみましょう。
第一引数に正規表現のパターン、第二引数に検索対象の文字列を記載する、とう書式ですね。flagsは少し複雑な正規表現の場合に使うケースがありますが、通常はdefaultのままでよいでしょう。変数として「pattern」と「string」を用意していけば確認していけそうですね。
任意の一文字
# 「.」任意の1文字
pattern='a.c'
strings=['abcd','abc','aac','ac']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
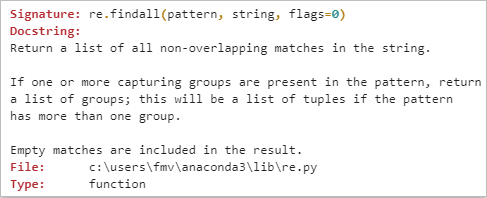
マッチした部分が結果として返ってくる点に注意が必要です。パターン「a.c」にマッチするのは「abcd」の「abc」の部分です。マッチした部分が返ってくるので、「abc」となっています。次に「abc」がマッチしてリストの2つ目は「abc」となっています。最後に「aac」もこのパターンにマッチするので「aac」がリストにありますね。最後の「ac」はマッチしないのでNoneが返ります。
0回または1回の繰り返し
# 「?」0回または1回の繰り返し
pattern='a?c'
string='abcd abc aac ac'
pattern='a?c'
strings=['abcd','abc','aac','ac']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()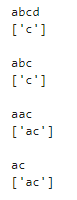
先ほどの「.」は任意の一文字なので必ず1つの文字が入るのですが、「?」は直前の文字の0回または1回の繰り返しなので、文字が入らない場合もあります。「abcd」でこの条件にマッチするのは「c」です。cの直前はaではないので、条件にマッチするのは「c」の部分だけとなります。同様に「abc」の部分もマッチしているのは「c」のみですね。次に「aac」については「ac」の部分がマッチします。cの前で「a」が0回または1回の繰り返しなので、「ac」の部分がこの条件にマッチしていますね。また最後の「ac」も同様にマッチします。
1回以上の繰り返し
# 「+」1回以上の繰り返し
pattern='a+c'
strings=['abcd','abc','aac','ac']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()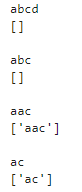
次は1回以上の繰り返しです。「abcd」の部分ではマッチしませんね。cの直前でaが1回以上繰り返される必要があります。次に「abc」の部分はどうでしょうか?こちらもcの直前がbなのでマッチしません。「aac」はcの直前でaが2回繰り返されるため「aac」の部分が条件にマッチします。「ac」も同様に考えて「ac」の部分が条件にマッチします。
先頭の文字
# 先頭の文字
pattern='^c'
strings=['abcd','cax','aaed','ccew']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()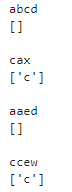
これは先頭の文字がcであるもののみがマッチします。これまでと同様に条件にマッチした部分のみが返ってくるため、返り値は「c」となります。
末尾の文字
# 末尾の文字
pattern='d$'
strings=['abcd','cax','aaed','ccew']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()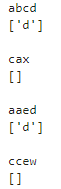
今度は末尾の文字がdであるもののみが抽出されます。こちらも今まで同様に条件にマッチした部分のみが返ってくるので、返り値は「d」となります。
m回の繰り返し
# m回の繰り返し
pattern='a{2}c'
strings=['abcd','caac','aaac']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
{2}は直前の文字を2回繰り返す意味になるので、「a{2}c」はaが2回繰り返されてその後にcが続きます。そのため「abcd」はマッチしない、「caac」「aaac」はともに「aac」という部分がマッチします。
m~n回の繰り返し
# m~n回の繰り返し
pattern='a{2,3}c'
strings=['abcd','caac','aaac']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
今度は繰り返し回数に幅がある場合です。「a{2,3}c」はaが2~3回繰り返されてその後にcが続くパターンとなります。「abcd」はマッチしない、「caac」では「aac」部分がマッチ、「aaac」では「aaac」部分がマッチします。
どれか
# どれかがマッチ:数字
pattern='a[0-9]c'
strings=['abcd','a45c','a8cd']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
[0-9]は0~9までの数字のどれかを表します。そのため「a[0-9]c」はaのあとに数字一文字、そのあとにcが続く、というパターンです。「abcd」は数字が含まれていないためマッチしない、「a45c」はaのあとに数字がきてさらに数字が来てしまっているためマッチしない、「a8cd」は「a8c」の部分がマッチします。
# どれかがマッチ:英字小文字
pattern='a[a-z]c'
strings=['abcd','a45c','a8cd']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
[a-z]はa~zまでの英字小文字のどれかを表します。そのため「a[a-z]c」はaのあとに英字小文字、そのあとにcが続く、というパターンです。「abcd」は「abc」の部分がマッチ、「a45c」「a8cd」はどちらもaのあとに数字がくるためマッチしません。
どちらか
# どちらかがマッチ:英字小文字
pattern='a[b|8]c'
strings=['abcd','a45c','a8cd']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
任意の数字
# 任意の数字
pattern='a\dc'
strings=['abcd','a4c','a8cd']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()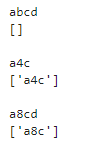
任意の数字は「\d」で表すことができます。これは[0-9]と同じ意味です。aとcの間に数字が一文字入った「a4c」と「a8c」がマッチします。
任意の数字以外
# 任意の「数字以外」
pattern='a\Dc'
strings=['abcd','a4c','a8cd']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()
今度は先ほどとは逆に任意の「数字以外」です。これを「\D」であらわすことができます。これは[^0-9]としても同じ意味になります。
任意の英数字・アンダースコア
# 任意の「英数字・アンダースコア」
pattern='a\wc'
strings=['a<c','a4c','a_c']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()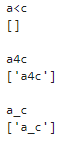
「\w」は任意の「英数字・アンダースコア」を表します。英数字は大文字でも構いません。「a<c」はaとcの間の記号はこれにマッチしません。「a4c」「a_c」はこの条件にマッチしますね。
任意の英数字・アンダースコア以外
# 任意の「英数字・アンダースコア以外」
pattern='a\Wc'
strings=['a<c','a4c','a_c']
for string in strings:
print(string)
print(re.findall(pattern,string))
print()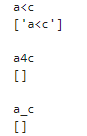
今度は先ほどの逆です。「¥W」は任意の「英数字・アンダースコア以外」を表します。そのため先ほどとは逆に「a<c」のみがマッチします。
まとめ
今回は正規表現のメタ文字・特殊シーケンスをざっとおさらいして、実際にコードで試してみました。表を見るだけではわかりにくくても、実際にコードで試すと見えてくるものがあると思います。自分でいろいろ試してみることで理解が深まると思うのでやってみましょう。
コメント