
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ Pandasの基本を解説しています。Series/DataFrameの作り方は以下をご覧ください。


はじめに
今回はデータを集計する際の必須操作となるgroupbyについて基本から解説します。groupbyはデータをグループ分けして共通の操作をする際に利用します。たとえば「営業部ごと」の売上とか「年代別」の平均利用金額のような集計です。基本から確認していきましょう。
groupbyの処理
groupbyを使った処理の基本的な流れ
まずはgroupbyを使って集計する際の処理の流れを確認しておきましょう。3つのステップで構成されます。
- グループ分け(split)
- 集計(apply)
- 結合(combine)
たとえば、身長のデータがあったとして男女別の平均を求めるとします。
まずはじめにおこなう処理は、データを「男性のデータ」と「女性のデータ」に分けることです。これが「1.グループ分け」です。
次に、求めたいのは男女別の身長の平均なので、「男性のデータ」「女性のデータ」それぞれに平均をもとめる関数を適用(apply)します。これが「2.集計(apply)」です。
最後に集計結果を集めて結合するのが「3.結合(combine)」です。
groupbyを使うと簡単にグループごとの集計ができますが、内部的にはこのような処理がされていることを理解しておくとイメージしやすいでしょう。
書式
書式を確認しておきましょう。基本的な書式は以下のようになります。
上記の書式で返されるのはGroupByオブジェクトである点に注意しましょう。実際に集計するには、このGroupByオブジェクトに対してさらにメソッドを指定します。
これが基本形になります。確認していきましょう。
サンプルデータの準備
今回はseabornにあらかじめ用意されているirisデータを使うことにしましょう。
# ライブラリのインポート
import numpy as np
import pandas as pd
import seaborn as sns
# irisデータの読み込み
df = sns.load_dataset('iris')
df.head()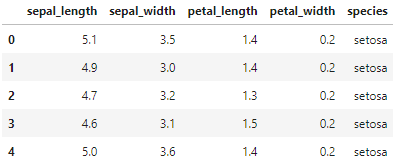
列(columns)でグループ分けする
irisデータのspeciesごとの平均を算出してみましょう。
# speciesごとの平均を算出
df.groupby('species').mean()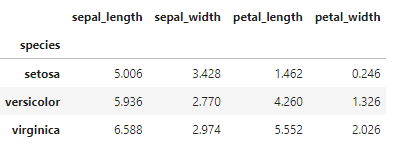
groupby()の中に列名を指定するだけです。このようにたった1行で「1.グループ分け」「2.集計」「3.結合」の操作をすることができます。書式のところで確認したように、メソッドを指定しなければGroupByオブジェクトが返されます。これも確認しておきましょう。
# GroupByオブジェクト
g = df.groupby('species')
print(type(g))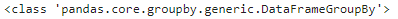
このようにgroupby(‘列名’)としただけでは、GoupByオブジェクトが返ってきます。どのようにグループ分けされたかを確認するには次のようにします。
# グループ分けの確認
g.groups
このように「setosa」「versicolor」「virginica」というグループに分けられたことがわかります。このデータは辞書型で、
{‘グループA’ : [data1, data2, data3,….],’グループB’:[data1, data2, data3,….]}
という形になっています。
行(index)でグループ分けする
あまり使うことがないかもしれませんが、indexでグループ分けすることもできます。今回はspeciesの列をindexに設定して、同じようにgroupbyしてみることにしましょう。
# speciesをindexに設定
df = df.set_index('species')
df.head()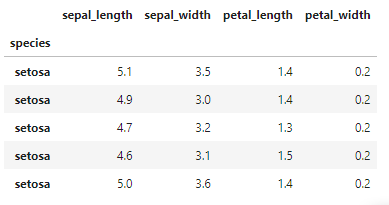
speciesをindexに設定することができました。この状態でgroupbyにindexを指定しましょう。先ほどと同様にindex名を指定するだけです。あるいはlevel=0を指定します。
# indexでgroupbyして平均を求める
df.groupby(level=0).mean()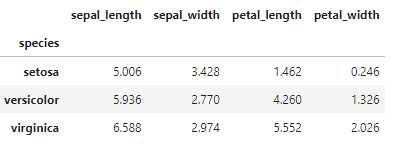
よくおこなう操作
最後にgroupbyを使ってよく行う操作を確認しておきましょう。先ほどの例のようにgroupbyした後、すべての項目の平均を求めたい場合は、groupby()に続けて.mean()とすればよいですが、一部の列のみ算出できれば良いときもありますね。そのときは、次のように列を指定します。
このようにグループ分けした後に、必要な列を指定して関数を適用するだけです。やってみましょう。
# speciesでグループ分けしてsepal_lengthの平均を求める
df.groupby('species')['sepal_length'].mean()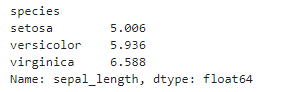
# speciesでグループ分けしてsepal_lengthの平均を求める df.groupby('species')['sepal_length'].mean()ちゃん取り出せていますね。次のようにすべての列の平均を計算してから、必要な列を取り出すこともできます。
# speciesでグループ分けして平均を求めてからsepal_lengthだけ取り出す
df.groupby('species').mean()['sepal_length']このコードでも先ほどと同じ結果が返ってきます。
次に最大値・最小値を求めることにしましょう。これも同様の操作です。
# spiceisでグループ分けをして各列の最大値を求める
df.groupby('species').max()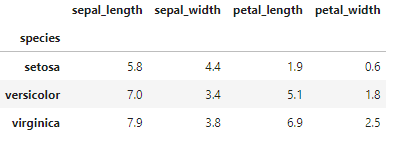
# spiceisでグループ分けをして各列の最小値を求める
df.groupby('species').min()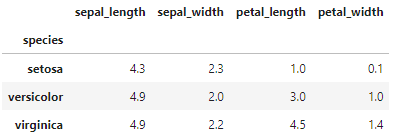
# spiceisでグループ分けをして各列の最小値を求める df.groupby('species').min()このように簡単にgroupbyでグループ分けをして各列の最大値・最小値を求めることができます。最大値を与えるレコードを抽出したいときは注意が必要です。各列で最大値を与えるレコードは異なるため、どの列の最大値を抽出したいのかを明確にする必要があります。
また、レコードを抽出する際にはmax()やmin()ではなく、最大値を与えるindexを返すidxmax()、最小値を与えるindexを返すidxmin()を使います。indexがわかれば、レコードの抽出は簡単です。iloc[]を使うのでしたね。
# speciesでグループ分けをしてsepal_lengthで最大値となるレコードを抽出する
df.iloc[df.groupby('species')['sepal_length'].idxmax()]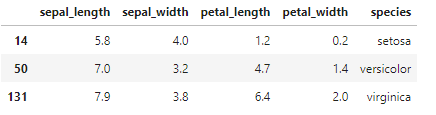
# speciesでグループ分けをしてsepal_lengthで最小値となるレコードを抽出する
df.iloc[df.groupby('species')['sepal_length'].idxmin()]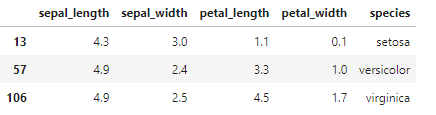
このようにsepal_lengthで最大値・最小値となるものを抽出することができました!
まとめ
今回はgroupby()の基本を解説しました。今回の内容をおさえておけば、基本的な集計は大丈夫でしょう。複数の列でgroupbyをするとどうなるか?applyを使った操作やaggを使った操作、などまだまだいろいろありますが、これらの操作は必要になった時に調べながら習得するとよいでしょう。
▶ groupbyのその他の操作はこちらの記事も参考にしてください。

コメント