
はじめに
今回は数値データのカテゴリ化を扱います。たとえば、売上データやアンケート結果では、各年齢のまま扱うよりも年代別のようにカテゴリ化したほうが、傾向がみやすくなることもあるでしょう。今回は年代別のカラムをあらたに作成して、集計する方法を学びましょう。今回は、pandasのcut()やqcut()メソッドを使わずにやってみましょう。
▶ 関数を使って数値データをカテゴリ化する方法は以下の投稿を参考にしてください。

サンプルデータ
今回も動物たちのデータです。動物たちの架空の売上データをつくりましょう。
# ライブラリのインポート
import pandas as pd
import math
# サンプルデータの作成
df_sample=pd.DataFrame({
'会員No':['C000023','C000032','Z000018','Z000021','C000023','Z000018','C000018','C000018','C000031','Z000032'],
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ','いぬ','おおかみ','かば'],
'年齢':[23,32,18,21,23,18,18,18,31,32],
'売上':[980,540,320,560,1200,430,980,1100,280,640]
})
df_sample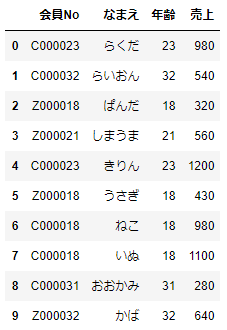
テーブルデータを扱うためにpandasをインポートするのは、いつも同じですが、今回は標準ライブラリであるmathもインポートしておきます。
どうぶつたちのデータは、会員No、おなまえ、年齢、売上、です。このデータから年齢別の売上に関するデータを整理しましょう。
年代別に集計する
まずは「年代別」のカラムを作ることを考えましょう。これは、簡単ですね。年齢を10で割って、小数点以下を切り捨てたのち10倍すれば10刻みの年代のデータになります。この「切り捨て」をおこなうのが、mathライブラリののfloorモジュールです。やってみましょう。
# 年代のカラムをつくる
df_sample['generation']=df_sample['年齢'].apply(lambda x:math.floor(x/10)*10)
df_sample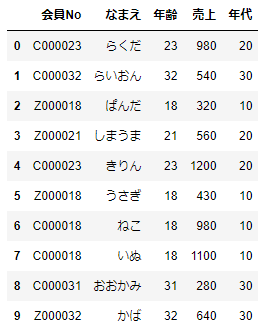
これで「年代」のカラムができました。あとは、年代別に売り上げに関する集計をしてみましょう。ここでは、売上合計と平均売上を求めてみましょう。
df_tmp=df_sample.groupby('年代').agg({'売上':['mean','sum']})
df_tmp.loc[:,'売上'].reset_index().rename(columns={'mean':'平均売上','sum':'売上合計'})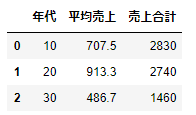
年代別の平均売上と売上合計を求めることができました。10代は20代と比べると、平均売上は低いですね。10代は学生が多くて支出が限られているのでしょうか?でも、30代は一転して、10代よりも低い平均売上です。世知辛い世の中で、節約しているのかもしれません。
まとめ
いかがでしたか?このようにデータ分析をしていると、数値データが与えられtらけど、あえてカテゴリ化をしたいケースがあります。今回示したような方法で、カテゴリ化したデータを集計することができます。
▶ データ分析時にはいろんな前処理があります。対数変換をする方法は以下の記事をご覧ください。

▶ 外れ値を除外する方法は以下をご覧ください。

コメント