
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ Pandasの基本を解説しています。Series/DataFrameの作り方は以下をご覧ください。


はじめに
今回はpandasのpivot_table()について基本を解説します。EXCELなどでデータ集計をするときによくおこなう操作なので、なじみ深い人も多いのではないでしょうか?ピボットテーブルはグループごとに集計して比較するときに使います。早速見ていきましょう。
ピボットテーブルによる集計
まずはサンプルデータを準備しましょう。今回はseabornライブラリにあらかじめ用意されている学習用のデータセット「tips」を使うことにしましょう。
# ライブラリのインポート
import pandas as pd
import seaborn as sns
# データの読み込み
df = sns.load_dataset('tips')
df.head()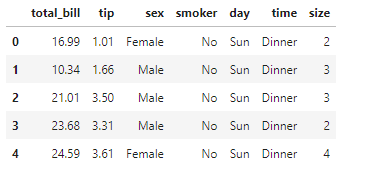
このデータを使ってピボットテーブルを確認していきましょう。まず初めに欠損値やデータの型などの要約情報を把握しておきましょう。
# データの要約情報の把握(行数・列数・列名・データの型・メモリ使用数など・・)
df.info()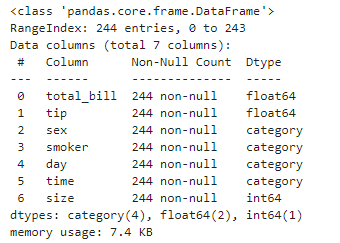
書式の確認
EXCELでピボットテーブルを触ったことがある方なら同じイメージで作ることができます。書式は次のようになります。
valuesにまず、集計した値を指定します。次にindex, columnsに集計軸を設定していくだけです。values, index, columnsは初期値はNoneになっているので集計したいデータにあわせて指定しましょう。また、agg_funcでは集計方法を指定することができます。こちらはdefaultでは平均(mean)となっているので注意しましょう。
pivot_table()による集計
データの準備ができたので早速やってみましょう。
# pivot_table()で集計
pivot_df = df.pivot_table(values='total_bill',index=['time','sex'],columns=['day','smoker'],aggfunc='count')
pivot_df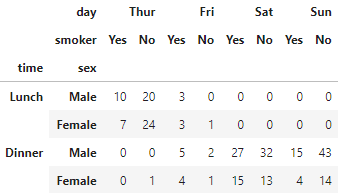
valuesには「total_bill」を指定していますが、aggfuncで「count」として数を数えているだけなので、ここは欠損していない項目ならなんでもよいです。
indexには、「time」と「sex」、columnsには「day」と「smoker」を指定しています。すると、これらの組み合わせでクロス集計ができます。簡単ですね!
集計結果から一部を抽出する
ピボットテーブルから一部を取り出す方法も確認しておきましょう。ピボットテーブルからデータを取り出すにはxs()を使います。xsはcross-sectionの意味です。
levelで指定したいindexの名称(あるいはcolumnsの名称)を指定し、keyではそのindex(あるいはcolumns)の中で抽出したい値を指定します。実際にやってみましょう。
# indexがtimeでその値がLunchのものを抽出
pivot_df.xs('Lunch',level='time',axis=0)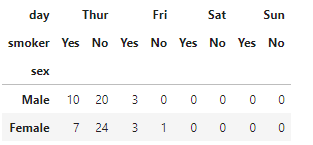
これは以下の部分を抽出しています。
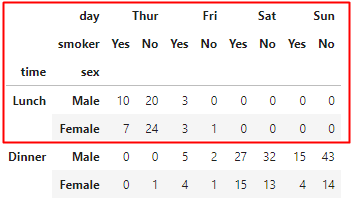
同じ要領でtimeを指定せずに男性だけのデータを抽出する場合は次のようにします。
# 男性だけのデータを抽出
pivot_df.xs('Male',level='sex',axis=0)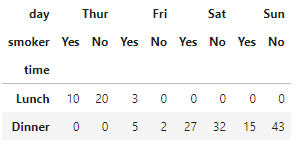
今度は以下の部分を抽出しています。
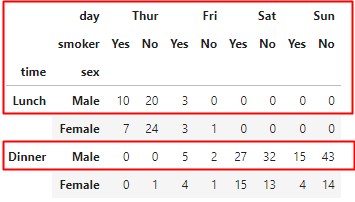
慣れると簡単ですね。これで、ピボットテーブルから自由に必要な部分を抽出できます。列方向についてもaxis=1とするだけで同様に操作できます。確認しておきましょう。
# smokerがYesの列を抽出
pivot_df.xs('Yes',level='smoker',axis=1)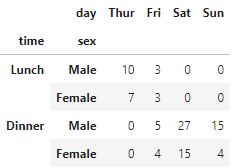
「smoker」の列が「Yes」のものを抽出しており、自明なのでdefaultではsmoker列がdropされていますが、これを表示させることもできます。drop_levelでFalseを指定します。
# 指定した列の情報も残して抽出
pivot_df.xs('Yes',level='smoker',axis=1,drop_level=False)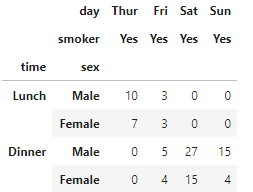
全部Yesになっているので無駄な気もしますが、説明しなくてもわかるというメリットもあります。この辺は好みの問題かもしれませんね。
まとめ
今回はピボットテーブルの基本について解説しました。ピボットテーブル自体はEXCELのイメージとほぼ変わらないですね。集計結果から必要な部分を抽出するには、xs()メソッドを使います。この使い方も是非、おさえておきましょう。
コメント