
Pythonでは「in」を使って指定した文字列が含まれるかチェックすることができます。今回はこの「in」の使い方を扱います。
やりたいこと
今回、この記事を書くきっかけになったのは、次のような作業をしていたときです。
本部から支社に対して毎月データを提示しています。このデータには該当支社に属する営業の方の、当月の実績が掲載されています。 但し、9月分は集計時のミスで誤ったデータを提示してしまいました。
<誤ったデータの内容>
①現在、指定した支社に属していない営業の方が掲載されていた
②現在、指定した支社に属している営業の方の一部が、掲載されていなかった
そこで、データを正しく集計しなおして再提示いたしました。支社に提示したデータは、
データA:集計時に誤ったデータ
データB:再集計した正しいデータ
となります。
すると、支社から次のような問い合わせが入ります。
「対象ではなかった営業と対象だったのに漏れていた営業を明らかにしてくれませんか?」
これに回答するためにデータAとデータBを使って作業をおこないます。
ここで扱っていたデータは次のような形になっていました。
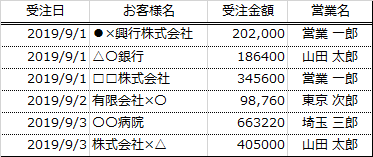
データAとデータBに含まれる営業の方をリストにしておいて、これをcommon_listのようにして、
- データAに含まれるが、common_listに含まれない営業のリスト
- データBに含まれるが、common_listに含まれない営業のリスト
とすればよさそうです。早速やってみましょう。
データの読み込み
# ライブラリの読み込み
import pandas as pd
# データの読み込み
old_list=pd.read_csv('old_list.csv',encoding='cp932')
new_list=pd.read_csv('new_list.csv',encoding='cp932')
これでデータA(old_list)とデータB(new_list)を読み込みました。今回のケースで気をつけなければならないのは、「営業名」はユニークではない、という点です。※月間の実績なので、同じ営業が複数の受注をして実績をあげています。
それぞれのデータフレームからリストを作る
そこで、まずはold_listの中に含まれる営業の方、new_listの中に含まれる営業の方をユニークにしてリストにしておきましょう。それぞれ、old_sa_list、new_sa_listとします。
# データAに含まれる営業名のユニークリスト
old_sa_list=pd.DataFrame({'営業名':list((old_list['営業名'].unique()))})
# データBに含まれる営業名のユニークリスト
new_sa_list=pd.DataFrame({'営業名':list((old_list['営業名'].unique()))})次にデータAとデータBに含まれる営業名のリスト(common_sa_list)をつくります。
# データAとデータBに共通で含まれる営業のリスト
common_sa_list=pd.merge(old_sa_list,new_sa_list,on='営業名')結果
あと一息です。すると、データAだけに含まれる営業の方のリスト(old_only_sa_list)とデータBだけに含まれる営業のリスト(new_only_sa_list)は次のように作ることができます。
old_only_sa_list=[]
new_only_sa_list=[]
for person in old_sa_list['営業名']:
if person in list(common_list['営業名']):
pass
else:
old_only_sa_list.append(person)
for person in new_sa_list['営業名']:
if person in list(common_list['営業名']):
pass
else:
new_only_sa_list.append(person) さらに
1つ注意点があります。pandas.seriesはリストのように扱えるため、in構文のときもそのまま使ってしまいがちです。(あ、私だけ?)
in構文は、pandas.seriesのままではうまく動きません。そのため、common_list[‘営業名’](←これはpandas.series)をlistで囲んで、pythonのリストとして扱っています。こうすることで、正しく、リストに含まれているかの判定をすることができます。
コメント