
はじめに
今回はスクレイピングを扱います。「requests」というwebページを取得するためのhttpライブラリと、「BeautifulSoup」というHTMLから情報を抽出するライブラリを使います。requestsでURLからHTMLを取得し、BeautifulSoupで要素を取得する、という使い方をします。
準備
requests
requestsはPythonのHTTP通信ライブラリです。インストールされていない場合は、次のコマンドでインストールしておきましょう。
pip install requests利用するときにはまずライブラリをインポートしておきます。
# ライブラリのインポート
import requestsHTTP通信ライブラリなので、get, post, put, etcなどのHTTPリクエストを生成することができますが、今回はスクレイピングをしたいので、getが使えればよいです。試しにこのブログのトップページを取得してみましょう。
response=requests.get('https://happy-analysis.com/')requests.get()ではresponseオブジェクトが生成されます。これを直接指定しても、次のようにステータスがわかるだけです。
response
requestオブジェクトから情報を取り出すには、属性を指定する必要があります。url属性にアクセスすると、次のようになります。
response.url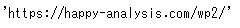
responseの内容(文字列)はtext属性で取得できます。
response.text
確かにHTMLは取得できていますが、このままだと見づらいですね。このHTMLを解析して必要な情報だけ抽出するのが、BeautifulSoupというライブラリの役割になります。
BeautifulSoup
まずインストールしておきましょう。
pip install beautifulsoup4無事インストールできたら、次のようにしてライブラリをインポートしておきましょう。
# ライブラリのインポート
from bs4 import BeautifulSoupこれで準備ができました。先ほど取得したHTMLを解析してみましょう。次のような書式で解析を実行します。
BeautifulSoup(解析対象,'html.parser')先ほど、取得したHTMLはresponse.textとなるので、簡単ですね。この解析結果をsoupという変数に格納することにしましょう。
# HTMLの解析
soup=BeautifulSoup(response.text,'html.parser')このsoupの中身を見てみましょう。
soup
これが解析結果です。読み込んだHTMLをそのまま表示しているようにも見えますが、先ほどのresponse.textよりも格段に見やすくなっていますね。BeautifulSoupの威力を発揮するのはここからで、このHTMLから必要な情報を抽出することができます。
BeautifulSoupを使って情報を抽出する
BeautifulSoupクラスのインスタンス(上記のsoupオブジェクトのこと)から情報を取り出す方法は、大きく分けてfind系(find_all( ), find( ))のメソッドと、select系(select( ), select_one( ))のメソッドの2種類がある。これらはできることはほぼ同じで、条件の指定方法が異なる。ここではfind系を扱うことにする。
find( )とfind_all( )の違いは、次の点です。
- find( )は引数に一致する最初の要素を1つだけ取得する
- find_all( )は引数に一致する要素をすべて取得する
find_all( )を使った解析の基本
ここではfind_all( )を使って解析してみましょう。まずはタイトルを取得してみましょう。
soup.find_all('title')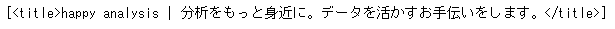
タイトル部分を取得することができました。このように、基本は、
soup.find_all('タグ名')という書式でタグを指定することで取得することができます。タグを階層で指定することもできます。
soup.body.div.li()
この例では、bodyの中のdivタグの中のliタグを抽出しています。このようにタグを「.」でつなぐだけです。簡単ですね!
タグだけではなく、クラスで条件指定したり、idでの条件指定、あるいは、これらの組み合わせでの条件指定もできます。
find_all( )の引数
find_all( )には次のような引数があります。
| name | タグを指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
| attrs | タグの属性を辞書で渡し指定する。 |
| recursive | Tagオブジェクトの検索対象範囲を指定。 True: Tagオブジェクトの全ての子孫要素を検索。 False: Tagオブジェクトの直下の子要素のみを検索。 |
| text | タグに挟まれているテキスト(文字列)を指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
| imit | 検索条件にマッチしたタグ・文字列の取得する数を制限する。 |
| キーワード引数 | タグの属性を指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
先ほどの「soup.find_all(‘title’)」は「soup.find_all(name=’title’)」とかいても同じ意味になります。引数が多いときは、明示的に書いてもよいかもしれませんね。
soup.find_all(name='title')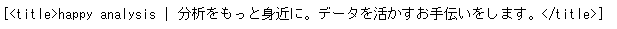
次にタグだけではなく、タグの属性も指定する場合です。
soup.find_all(name='a',class_='home_menu')
aタグの中で、class属性が「home_menu」であるものを抜き出しました。属性の指定では、通常、属性をそのまま記述すればよいのですが、classだけは予約語となるので、「class」ではなく「class_」とします。
次に属性を複数指定する場合を見ておきましょう。このブログのソースを見ると、次のような部分があります。

「class」属性に複数の値が設定されています。この部分を指定してみましょう。これは次のように書きます。
soup.find_all(name='li',class_="clearfix num1 type1")
このように、classが「clearfix num1 type1」であるものに完全一致させて、抽出することができました。完全一致ではなく、部分一致にさせたいときには、次のように書きます。
soup.find_all(name='li',class_=["clearfix","type1"])idの指定も見ておきましょう。表にまとめたように属性の指定は「属性名」とその値を指定するだけなので、次のように指定できます。(※classだけは予約語だったので、「class_」とします。)
soup.find_all(name='ul',id='menu-python')
「class_」の指定の時とまったく同じ要領ですね。複数選択で部分一致させるときも同じように角括弧で指定します。
引数「text」も見ておきましょう。こちらは、タグに挟まれているテキストを指定します。
soup.find_all(text='分析環境の構築')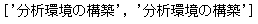
2件ヒットしました。この指定は完全一致になるので、たとえば次のようにテキストの値に「分析」を指定した時では、検索結果が異なります。
soup.find_all(text='分析')
今回取得したHTMLの中にはタグの間に「分析」とだけ書かれている箇所はなかったので、結果はnullになりました。部分一致で「分析」という文字がが含まれているものを抽出したいときには、正規表現を用いて次のようにします。
# 正規表現ライブラリのインポート
import re
# text引数と正規表現を使った条件指定
soup.find_all(text=re.compile('分析'))
このように正規表現を組み合わせると条件指定の幅が広がります。属性の指定の場合も、たとえばhref属性である文字列を含むURLを抽出したければ次のように記述できます。
soup.find_all(href=re.compile('python-topic-summary-basic'))
まとめ
いかがでしょうか?だいぶイメージできるようになりましたか?まずは取得したいHTMLのソースを見ながら大体の条件指定を考えて、何度か試してみるとよいでしょう。
コメント