
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方

はじめに
今回はMultiindexについて基本から解説します。groupbyで処理をした後、MultiIndexになって扱いに困ったことはありませんか?通常のデータフレームとは少し操作が違うため始めは戸惑ったのではないでしょうか?Multiindexは慣れてしまえばそんなに難しくありません。基本から解説していきます。
MuliIndexを使いこなす
サンプルデータを用いて実際にコードを書いて実行結果を見ながら解説していくことにしましょう。今回はどうぶつたちがおこなった業務のデータで試していきましょう。
サンプルデータ
以下のようなデータを使うことにしましょう。データは「_data」という変数にいれてあります。
# データの確認
_data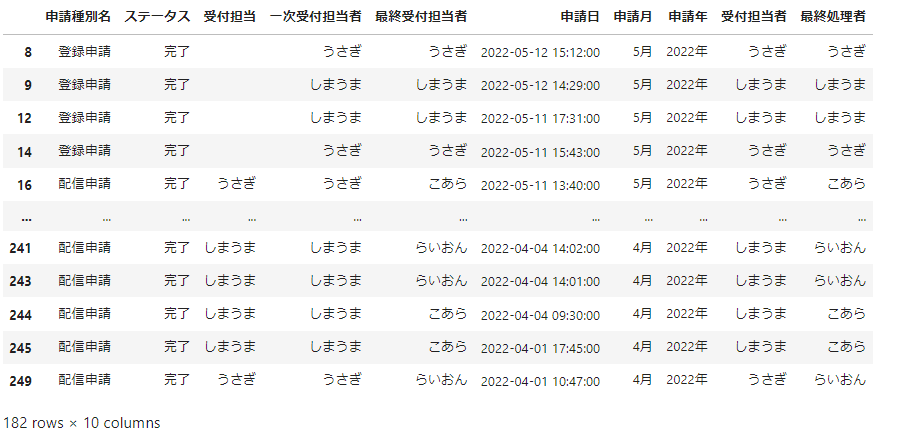
どうぶつたちが処理した業務を記録したデータです。1つの申請をまずは受付担当者が処理して、最終処理者に渡します。1つの申請ごとに記録がとってあり、受付担当者、最終処理者が誰であったかが記録されています。
少しデータをみてみましょう。。申請種別ごとにどうぶつたちが、一次受付担当・最終受付担当を何件処理したかをします。
# groupbyによる集計処理
data_df=_data.groupby(['申請月','申請種別名']).\
agg({'一次受付担当者':'value_counts','最終受付担当者':'value_counts'}).fillna(0)
data_df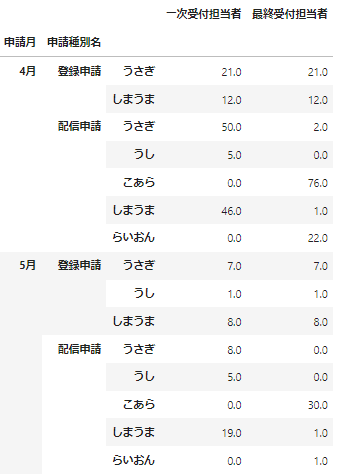
申請内容ごとにどうぶつたちがどの役割(一次受付・最終受付)を何件おこなったのかがわかりやすくなりましたね。いま、このデータはインデックスが階層構造になっています。このようなデータを階層型インデックス(MultiIndex)といいます。
このデータのインデックスを確認してみましょう。
data_df.index
このようにMultiIndexになっていることが確認できますね。indexの名称はnames属性で取得することができます。
# names属性
data_df.index.names
データの整形
まずはMultiIndexのデータの整形方法を学んでいきましょう。まずは、index⇔columnsを自由に入れ替えする方法から見ていきましょう。
indexをcolumnsにする(unstack)
indexをcolumnsにするにはunstack()を使います。行方向に積み重なっていた(stack)ものを解除する(unstack)イメージなんでしょうね。きっと。
unstackは引数levelをとります。levelはindex名あるいは数字で指定することができます。やってみましょう。
# indexをcolumnsに
data_df.unstack(level='申請種別名')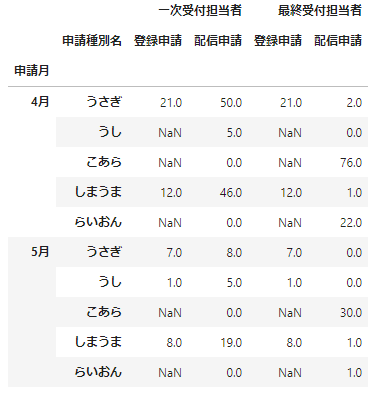
うまくいきましたね。これは「data_df.unstack(level=1)」としても同じ結果が得られます。また、NaNの部分はfill_valueという引数で置き換えをすることができます。今度はlevelを数字で指定して、NaNは0で置き換えてみましょう。
# levelを数字で指定してNaNを0で置き換え
data_unstacked=data_df.unstack(level=1,fill_value=0)
data_unstacked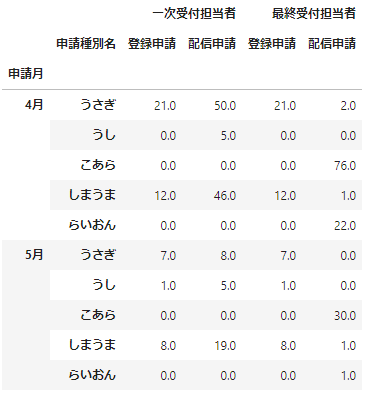
簡単ですね。indexもcolumnsも階層構造となっていますね。このようなデータからの行・列の抽出は後半に扱うことにして、次はcolumnsをindexにする操作もみていきましょう。
columnsをindexにする(stack)
今度は先ほどとは逆の操作です。この操作はstack()を使います。先ほどunstackしたデータdata_df_unstackedに対して操作をしてみましょう。data_df_unstackedは以下のデータです。
# データの確認
data_df_unstacked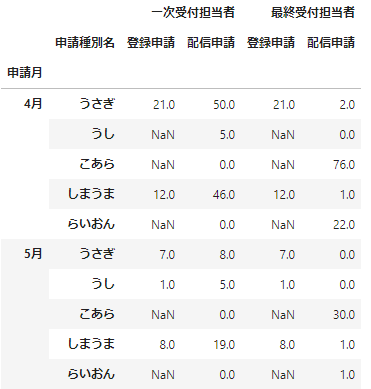
先ほどの逆の操作としてcolumnsにある「申請種別名」をindexに移してみましょう。
# columnsにある「申請種別名」をindexに移す
data_df_unstacked.stack(level='申請種別名')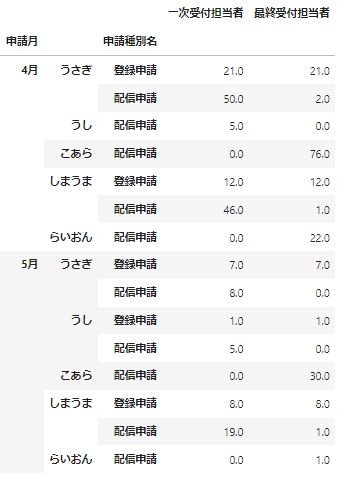
もちろん、levelを数字で指定することもできます。
# columnsをindexに移す
data_df_unstacked.stack(level=0).fillna(0)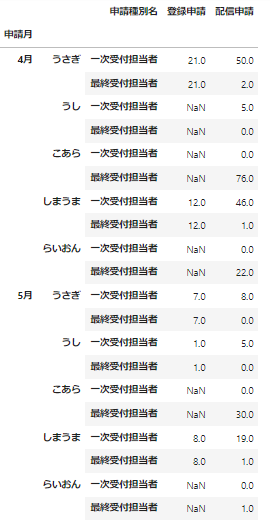
簡単ですね。
levelの順番を入れ替える(reorder_levels)
次にlevelの順番を入れ替えてみましょう。data_df_unstackedを使って試していきましょう。このデータのColumnsは外側(level0)には名前がついていない(None)、内側(level1)は申請種別名でした。levelを数字で指定する場合は次のようにします。
# 数字でレベルを指定
data_df_unstacked.reorder_levels([1,0], axis=1)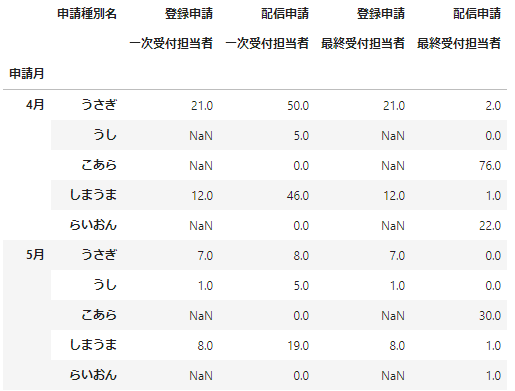
ちゃんとできていますね。columnsの階層を入れ替える場合には、axis=1の指定を忘れないようにしてください。
level部分を名前で指定することもできます。今回の例のように名前が指定されていない場合は
Noneとなります。
# 名前でレベルを指定
data_df_unstacked.reorder_levels(['申請種別名',None],axis=1)うまくいきましたね。ただ、この出力はちょっと見にくいですね。外側の階層ごとにデータが並んでいる方が見やすい場合もあるでしょう。その場合はsort処理をする必要があります。
sort処理(sort_index)
階層ごとに並び替える場合には、sort_indexを使います。やってみましょう。
# 階層ごとに並び替える
data_df_unstacked.reorder_levels(['申請種別名',None],axis=1).sort_index(level='申請種別名',axis=1)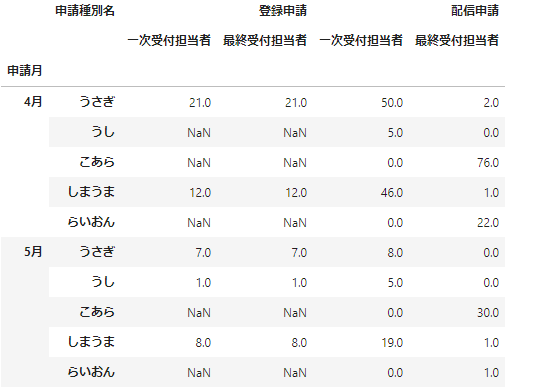
行・列の選択
階層の一番外側の情報を使った選択(locで任意の行・列を選択)
MultiIndex構造で、行・列を選択するときにうまくいかなかったことはありませんか?MultiIndexのときにはこれまでの選択方法と異なる部分もあるので注意しましょう。
とはいえ、はじめにしっかりやり方を理解しておけば難しくないので心配いりません。まず、MultiIndexでも一番外側の行・列の情報で指定する場合は通常のlocと変わりません。data_df_unstackedで一次受付担当者を指定してみましょう。
# MultiIndexの外側の行・列を指定する場合
data_df_unstacked.loc[:,'一次受付担当者']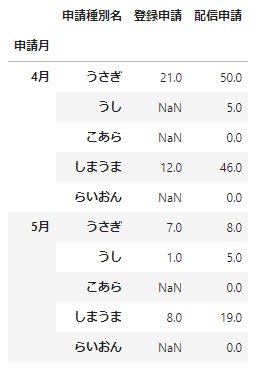
このように通常のデータフレームと同じ感覚で操作できますね。外側の行・列を使う場合は、スライスも問題なく使えます。
# スライスを使った指定
data_df_unstacked.loc['4月',:]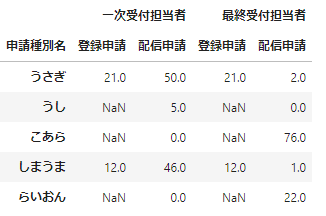
外側の階層から順に絞り込む場合
この場合はタプルで順に値を指定します。やってみましょう。今回はdata_dfのデータを使います。
# タプルで指定する
data_df.loc[(['4月','5月'],'配信申請',['うさぎ','しまうま','らいおん']),:]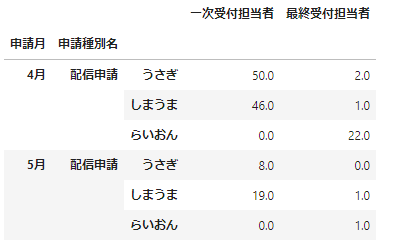
タプルで順に指定する場合、リストは使えるがスライスはエラーとなるので注意しましょう。
# タプルで指定する(タプルは使用できない)
data_df.loc[(['4月','5月'],:,:),:]タプルで指定する部分(タプルの中)では、スライス表記が使えません。スライス表記で指定たい場合は、次で扱う特殊なスライス指定を使うとよいでしょう。
特殊なスライス指定: slice, pd.IndexSlice
pandasにはIndexSliceがあります。これを使うと、階層の一番外側の時だけではなく、外側から打ち合わせに絞り込む場合でもスライスによる指定が容易にできます。idxを定義したうえで次のようにできます。
idx = pd.IndexSlice
data_df.loc[idx[['4月','5月'],:,:],:]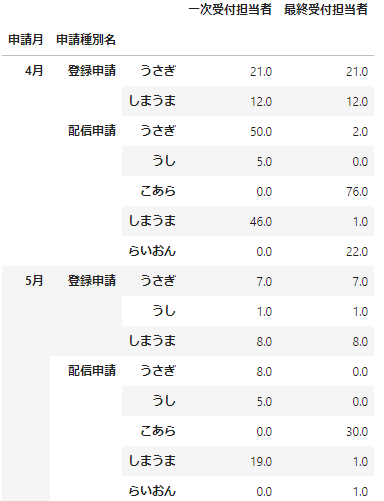
うまくいきました。このようにスライス表現が使えると、これまでのlocと同じように使えるので直感的に操作できて便利ですね!
まとめ
今回はMultiIndexについて扱いました。まず、Index⇔Columns間で自由にデータの整形ができるようにstack/unstack、levelの入れ替えをするreorder_levels、並び替えをするsort_indexの説明をおこないました。その後、MultiIndexの行・列を選択する方法としてlocを使う場合、pd.IndexSliceを使う方法をご紹介しました。
コメント