
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方

はじめに
今回はjsonファイルの読み書きの基本を解説します。Webでのデータの送受信に使われるデータ形式なのでよく目にすることもありますね。ただ、基本を知らないとどうしてよいかさっぱりわからないですよね。今回はjsonファイルの取り扱い方を基本から丁寧に解説していきます。
▶ jsonをpandasで扱う方法は以下の記事をご覧ください。

jsonフォーマットを使うパターン
jsonフォーマットのデータを使う際は大きく分けると、次の2パターンがあります。
- jsonファイルを扱う
- json文字列を扱う
最初の「jsonファイルを扱う」はjson形式で書き込まれた「ファイル」を扱う場合です。「json文字列を扱う」は、文字通りjson形式の「文字列」を直接扱う場合です。この2パターンにわけて解説していきます。
jsonファイルを扱う
▶ Pythonでのファイルの読み書きの基本は以下の記事を参考にしてください。

jsonファイルを読み込む
まずはjsonファイルを読み込む場合です。jsonは構造化データなのでプレインテキストとして扱うよりも専用のモジュールを使って読み込むほうがよいでしょう。ここでは「json」モジュールを使います。
import json
with open('sample.json') as f:
data=json.load(f)まず1行目でjsonモジュールをimport しています。3行目でファイルを開いています。これは通常のテキストファイルと同様です。今回は同一ディレクトリに「sample.json」というファイルを用意しているので、「open(‘sample.json’)」としています。jsonのサンプルファイルは「JSON GENERATOR」というサイトで作りました。
4行目でファイルの内容を読み込んでいます。jsonモジュールにはload()メソッドがあり、ファイルオブジェクトを指定するとpythonのディクショナリ形式で受け取ることができます。
いま、dataにはjsonファイルを読みこんでPythonのディクショナリ形式にしたものが格納されています。見てみましょう。
# データの確認
data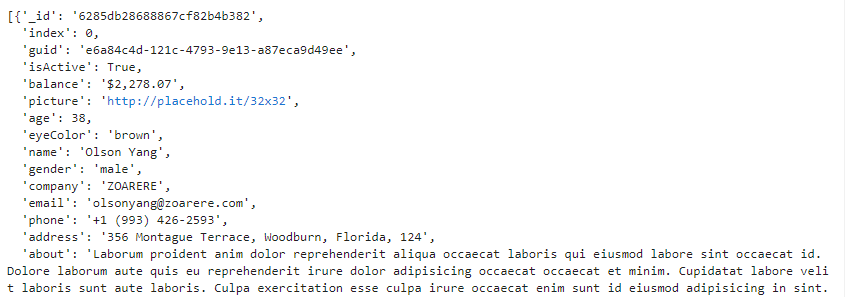
このようにPythonのディクショナリ形式となっています。サンプルデータは長いので上の出力結果は省略しているのでわかりにくいですが、辞書型データがリストで格納されている形になっています。
これを確認しておきましょう。
# データ型と要素数の確認
print(f'dataの型は{type(data)}です')
print(f'要素の数は{len(data)}です')
dataはリスト型で要素数が7個であることがわかりました。次にこのデータ型の要素を取り出してその型を見てみましょう。ここでは一番初めの要素を取り出して型をみてみます。
# 一番最初(の要素の型を調べる
type(data[0])
ちなみにデータフレームとして読み込むのであれば、次のようにすると簡単です。
import pandas as pd
data_df = pd.read_json('sample.json', typ='frame')
data_df.head(3)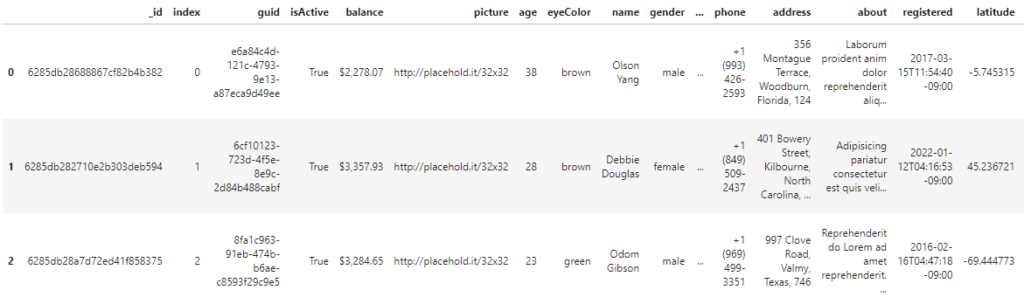
次に書き込みについても見ていきましょう。
jsonファイルに書き込む
Pythonの辞書型データをjsonファイルに書き込むことにしましょう。まずは、Pythonの辞書型データを準備します。
# 辞書型のデータを準備
data_dic = {
'id':[0,1,2,3,4,5],
'sex':['male','female','female','female','male','male'],
'age':[28,41,32,51,32,35]
}このデータをjsonファイルに書き込むことにしましょう。
with open('sample_create.json', mode='w') as f:
json.dump(data_dic, f)たったこれだけです。簡単ですね。openの第一引数にファイル名を指定します。ファイルがない場合は新規作成、既存ファイルの場合は「上書き」がされます。いま、このファイルオブジェクトを「f」と定義しているので、2行目ではdump()メソッドの第二引数にこのファイルオブジェクト「f」を指定しています。第一引数はファイルに書き込みたいデータを指定するので、先ほど作ったPythonのディクショナリ形式のデータdata_dicを指定しています。
ちゃんと書き込まれているかをpandasのデータフレームに読み込んで確認してみましょう。
df = pd.read_json('sample_create.json', typ='frame')
df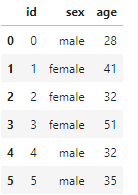
ちゃんとできてますね。では、次にjson文字列を直接扱う場合もみていきましょう。
json文字列を扱う
json文字列を読み込む
jsonファイルを読み込む時と似ていますが、json文字列を読み込む場合は、loads()メソッドを使います。ファイルの読み込み時はload()メソッド、文字列の読み込み時はloads()メソッドとなります。loadsの最後の「s」は「string(文字列)」の「s」ですね。これも試してみましょう。
# json文字列
json_str='''
# json文字列
json_str='''
{"id": [0, 1, 2, 3, 4, 5],
"sex": ["male", "female", "female", "female", "male", "male"],
"age": [28, 41, 32, 51, 32, 35]}
'''
# json文字列の読み込み
json.loads(json_str)
pythonのディクショナリ形式で読み込まれていますね。ファイルの読み込みはload()メソッド、json文字列の読み込みはloads()メソッドと覚えておけば難しくないですね。
json文字列を返す
最後にjson文字列を返す操作も確認しておきましょう。こちらもjsonファイルに書き出す場合と似ています。json文字列を返す操作はdumps()メソッドを使います。ファイルの書き込み時はdump()メソッド、文字列を返す時はdumps()メソッドとなります。こちらもdumpsの最後の「s」は「string(文字列)」の「s」ということですね。これも確認しておきましょう。
先ほど作った、python辞書形式のデータ「data_dic」を使って試します。
# 辞書形式のデータをjson形式にする
json.dumps(data_dic)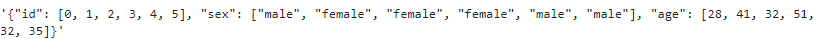
うまくいきましたね。慣れてしまえばどうということはないですね。
まとめ
今回はjson形式のデータの取り扱い方法を解説しました。jsonファイルを扱う場合とjson形式の文字列を扱う場合に分けて解説しました。
コメント