
▶ まずデータの概要をつかむなら、以下の記事を参考にしてください。基本統計量をまとめて算出する方法をご紹介しています。

▶ 分散/標準偏差に関する解説はこちらの記事を合わせてお読みください。

はじめに
今回は最頻値を扱います。いまになって「最頻値」という感じもしますが、一度整理しておきましょう。pandas.Seriesを対象とする場合、pandas.DataFrameを対象とする場合で考えることにしましょう。
最頻値をもとめる
サンプルデータの作成
まずはサンプルデータをつくりましょう。何度か使った、動物園のデータを使うことにしましょう。つぎのコードでデータを作成してください。
# サンプルデータの作成
df_sample=pd.DataFrame({
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ','いぬ','おおかみ','かば'],
'動物園':['上野動物園','旭山動物園','上野動物園','こどもどうぶつえん','ズーラシア','ズーラシア','旭山動物園','旭山動物園','ズーラシア','こどもどうぶつえん'],
'年齢':[23,32,18,21,23,18,18,18,31,32]
})
df_sample
全レコードを対象にある特徴量の最頻値を求める
ある特徴量の最頻値を求めたい場合は、次のようにデータフレームから、最頻値を求めたい特徴量を指定してpandas.Seriesのメソッドmode()を使って求めることができます。たとえば、動物園の最頻値を確認するなら次のようになります。
df_sample['動物園'].mode()
このように同数のものが複数ある場合は、いずれも表示されます。年齢で試すと次のようになります。
df_sample['年齢'].mode()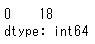
データフレームにある特徴量のすべての最頻値を調べたければ、このように一つずつ指定する必要はありません。次のように、データフレームに対してmode()メソッドを適用すると、まとめて表示させることができます。
df_sample.mode()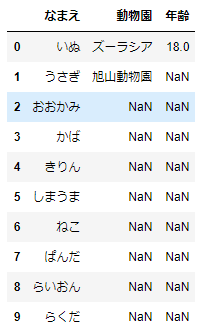
動物たちのなまえはみんな異なるので、すべて頻度1で最頻値として表示されています。動物園については、ズーラシア、旭山動物園がそれぞれ3回ずつで、同数なのでどちらも示されます。年齢に関しては、18が3回で単独の最頻値なのでこれだけが表示されています。
指定した特徴量ごとにある特徴量の最頻値を求める
次に動物園ごとに、年齢の最頻値を求めてみましょう。これは、groupbyとlambdaを使って次のようにおこないます。
df_sample.groupby('動物園')['年齢'].apply(lambda x:x.mode()).reset_index()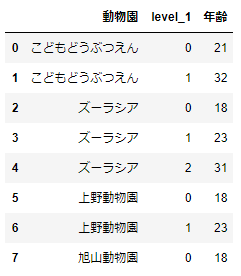
旭山動物園では、32歳、18歳、18歳の動物たちがいたので、最頻値18が表示されています。そのほかの動物園では、それぞれの年齢が1名ずつだったので、同順のためすべて表示されています。
まとめ
いかがでしたか?データ分析では頻度を扱ったり、順位をつけたりすることが結構ありますね。ぱっと求められるように身につけておくとよいでしょう。
▶ 四分位数の解説や、四分位数を使った外れ値の除外に関する記事もあります。

▶ 一気にデータの概要を把握する方法があります。こちらの記事をどうぞ。

コメント