
はじめに
今回は分類モデルの性能評価指標について考えてみます。性能評価指標は複数あり、設定した課題によってどの指標を重視するかは異なります。この性能評価の各指標を簡単に確認することができる、混同行列もご紹介します。
性能評価指標
性能評価指標には次のようなものがあります。
- 正解率(Accuracy):全てのデータで判定結果が合っていたかどうかを算出
- 適合率(Precision):陽性であると予測したうち、実際に陽性である割合を示す
- 再現率(Recall):本当に陽性であるケースのうち、陽性と予測できた割合を示す
言葉で説明するとこうなのですが、これを理解するには次に紹介する混同行列の表現がわかりやすいと思います。
混同行列
簡単にいうと、混同行列は予測結果と実際を比較してどのくらい正解していたか、をみるものです。どのくらい正解していたか、整理したクロス集計表の中で全体でみる、行方向でみる、列方向でみる、によって各性能評価指標が決まります。簡単な例で見ていきましょう。
| Negative(陰性)と予想 | Positive(陽性)と予想 | Recall(再現率) | |
| 実際の値がNegative(陰性) | TN | FP | TN/(TN+FP) |
| 実際の値がPositive(陽性) | FN | TP | TP/(FN+TP) |
| Precision(適合率) | FN/(TN+FN) | TP/(FP+TP) |
行方向を実際の値、列方向を予測としてクロス集計したときには、行方向の割合を計算したものがRecall(再現率)、列方向の割合を計算したものがPrecision(適合率)となります。また、全体に対する正解の割合(TP+TN)/(TP+FN+FP+TN)がAccuracy(正解率)となります。
どの指標を重視するか
機械学習でモデルを作成したときに、正解率を見ることが多いですが、どれだけ成果したか、をみる正解率だけをみるのは不十分です。これは、たとえば、例えば100個のデータがあって90個がPositive(陽性)、10個がNegative(陰性)である場合、「全てのデータをPositive(陽性)」と予測しても正解率は90%になりますがNegative(陰性)に対する予測は全て外しているのでこれではちゃんと予測できているとは言えません。このように、正解率だけを見ていてはモデルの性能評価として不十分です。
Precision(適合率)とRecall(再現率)には、トレードオフの関係があります。そのため、解決したいテーマごとにどの指標が重要であるかを考える必要があります。参考までに適合率を優先する場合、再現率を優先する場合にどのようなものがあるか考えてみましょう。
- 適合率を優先する場合
スパムメールの判定などは、適合率を優先する例になるかと思います。この場合Positive(陽性:スパム)、Negative(陰性:スパムではない)としたときに、スパムと予測したものが、実際にスパムである割合を重視するということです。適合率>再現率としているので、実際にはスパムメールであってもスパムと判定されない、というケースをある程度許容することで、重要なメールがスパムと誤判定されてないようにします。 - 再現率を優先する場合
癌の検査の場合などは、再現率を優先する例になるかと思います。この場合は、Positive(陽性:癌である)、Negative(陰性:癌ではない)としたときに、実際に癌である人が、癌である、と予測して抽出できることが重要ということです。
ややこしいですが(私もなんどもよくわからなくなりました・・)、誤解を恐れずに表現すると、「適合率は予測が正解することが重要で、陰性を陽性と誤判定したくない」「再現率は実際の陽性を抽出することが重要で、陰性を陽性と誤判定することをある程度許容する」と考えると理解できた気になりました。
では、次のようなテーマではどうでしょうか?
「あるシステムに対して、外部からアクセスがあった場合にそれがシステムへの攻撃であるか否かを判定する(#攻撃の場合を陽性とする)このとき、陽性の場合にはアクセスを遮断して、システムを利用できないように制御する。」
この場合、適合率と再現率のどちらを重視するとよいでしょうか?これは、一概には言えないのですが、何を重視するか、によります。
ユーザーのアクセスを重要視する場合は、適合率を重視するでしょうし、システムには重要な資産があるため、しっかり保護したい場合は再現率を重視するでしょう。前者の場合は、ユーザーのアクセスを重視するため、陰性のユーザーを陽性と誤判定して遮断することはしたくないので適合率を重視し、後者の場合は、攻撃を抽出することが重要で、実際には攻撃していないユーザーの一部誤判定を許容して再現率を重視する、ということです。
混同行列をもとめる
混同行列もskleranに用意されています。簡単な例で試してみましょう。行動行列は、実際の値(行方向)と予測した値(列方向)のクロス集計ですから、次のようなデータを用意してみましょう。
# 実際の値と予測値のデータを作成
true = [0, 0, 0,1, 0, 0, 1, 0, 0, 0, 1,1,0,0,0,1,1,1,0,1]
pred = [0, 0, 1, 0, 0, 1, 0, 0, 0, 0,1,1,1,0,0,1,1,0,1,1] ここでは、実際の値と予測値のデータを直接作成しました。このデータをもとに混同行列をもとめてみましょう。sklearnには、confusion_matrixが用意されています。次のようにしてください。
# ライブラリのインポート
from sklearn.metrics import confusion_matrix
# 混同行列を求める
confusion_matrix(true, pred)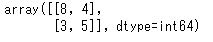
これは、TN=8、FP=4、FN=3、TP=5ということです。そのため、再現率、適合率、成果率は次のように求められます。
再現率=5/(3+5)=0.625
適合率=5/(4+5)=0.556
正解率=(8+5)/(8+5+4+3)=0.65
各性能評価指標をもとめる
先の例のように、混同行列をもとめてその要素から各性能指標をもとめてもよいのですが、sklearnではこれらの指標も簡単に求められるようになっています。
再現率
# ライブラリのインポート
from sklearn.metrics import recall_score
# 再現率の算出
print(recall_score(true, pred))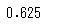
適合率
# ライブラリのインポート
from sklearn.metrics import precision_score
# 適合率の算出
print(precision_score(true, pred))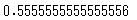
正解率
# ライブラリのインポート
from sklearn.metrics import accuracy_score
# 正解率の算出
print(accuracy_score(true, pred))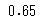
まとめ
いかがでしたか?今回は分類問題における性能評価指標について扱いました。解決したい課題ごとにどの性能評価指標を重視するかを検討することが大切です。前半は各性能評価指標の意味、後半はsklearnで、混同行列とこれらの性能評価指標を算出する方法をご紹介しました。
コメント