
▶ いろんな前処理を扱っています。都道府県の処理は以下の投稿をどうぞ。

はじめに
データ分析をしていると、特定の列が一致しないものを抽出したい時があります。前回は、データフレームの中で特定の列の差分がわかればよかったので、リスト化をおこないました(指定した文字列が含まれるかどうかチェックする)が、今回は特定の列が一致しないデータフレームを抽出する方法を紹介します。isinを利用します。
やりたいこと
前回と同様、次のようなデータを扱います。
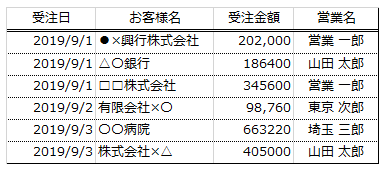
このようなデータフレームが2つ(df1とdf2)あり、それぞれのデータフレームの「営業名」を比較して、
・df1にはあって、df2にはない「営業名」を持つ行をdf1から抽出したい
・df2にはあって、df2にはない「営業名」を持つ行をdf2から抽出したい
となります。
データの準備
df1=pd.DataFrame({'受注日':['2019年9月1日','2019年9月1日','2019年9月1日','2019年9月2日','2019年9月3日','2019年9月3日'],
'お客様名':['●×興行株式会社','△〇銀行','□□株式会社','有限会社×〇','〇〇病院','株式会社×△'],
'受注金額':[202000,186400,345600,98760,663220,405000],
'営業名':['営業 一郎','山田 太郎','茨城 一郎','東京 次郎','埼玉 三郎','山田 太郎']})
df2=pd.DataFrame({'受注日':['2019年9月1日','2019年9月2日','2019年9月3日','2019年9月3日','2019年9月4日'],
'お客様名':['●×興行株式会社','有限会社×〇','〇〇病院','株式会社×△','□〇産業'],
'受注金額':[202000,98760,663220,405000,205000],
'営業名':['営業 一郎','東京 次郎','埼玉 三郎','山田 太郎','神奈川 四郎']})このコードで次のような2つのデータフレームを作ることができます。
df1
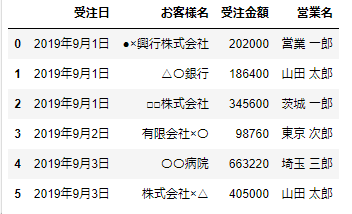
df2
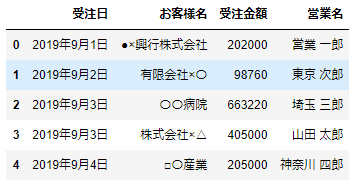
結果
データを眺めてみると、各データフレームにいる営業の方は以下のようになります。
df1:「営業 一郎」「山田 太郎」「茨城 一郎」「東京 次郎」「埼玉 三郎」「山田 太郎」
df2:「営業 一郎」「東京 次郎」「埼玉 三郎」「山田 太郎」「神奈川 四郎」
df1にいてdf2にいない営業の方は、「茨城 一郎」さん、
df2にいてdf1にいない営業の方は、「神奈川 四郎」さんとなります。
すると、次のように抽出することができます。
df1にいてdf2にいない営業の方のデータ
# df1にいてdf2にいない営業の方のデータ
df1[~df1['営業名'].isin(df2['営業名'])]
# df2にいてdf1にいない営業の方のデータ
df2[~df2['営業名'].isin(df1['営業名'])]このコードで次のような結果が得られます。


さらに
この方法は、2つのデータフレームから列を取り出してそれらが一致しているかを比較しているため、同じ営業の方が複数レコード合ってもうまくいきます。たとえば、次のようなdf3を考えてみます。
df3
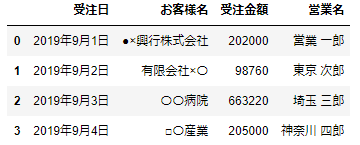
今回は、df1にいてdf3にいないのは、「山田 太郎」「茨城 一郎」さんとなります。df1をみてみると、「山田 太郎」さんは2レコード、「茨城 一郎」さんは1レコードあります。これを抽出するには、次のようにします。
df1[~df1['営業名'].isin(df3['営業名'])]すると、次のように結果が得られます。
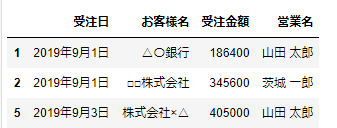
これで無事、抽出したいデータを得ることができました。ちなみに「~(チルダ)」はNot演算を表します。今回は、共通ではない部分を取り出すため、df1[~df1[‘営業名’].isin(df2[‘営業名’])]のようにしてますが、 df1[df1[‘営業名’].isin(df2[‘営業名’])] のようにすると、共通部分を取り出すことができます。
▶ データ分析の過程では様々な前処理があります。以下も必須の内容となります。


コメント