
はじめに
今回はビン分割の方法を扱います。ビン分割は連続データを区切ってカテゴリ分けする操作です。年齢を年代別にしたり、体重を階級別にしたりするような操作となります。pandasにcut( ),qcut( )が用意されています。この違い・使い方についてみていきましょう。
サンプルデータ
200人分の身長のデータを作ることにしましょう。
# idと身長のデータを作成
id=list(range(200))
data=[random.randint(150, 195) for i in range(200)]
# データフレームの作成
height_data=pd.DataFrame({'id':id,'身長':data})
height_data.head()
ビン分割
cut( )とqcut( )の違いは、値をもとに分割するか(cut)、量をもとに分割するか(qcut)の違いです。
- cut
cutは値をもとに分割する方法です。境界値を指定して分割します。 - qcut
qcutは量をもとに分割する方法です。値の大きさ順に並べて、指定した数で等分します。
まずはcutから見ていくことにしましょう。
cut( )
これを身長のデータだとして、150~155,156~160,161~165,166~170,171~175,176~180,181~185,186~190,191~195にわけることにしましょう。
# cutでビン分割
pd.cut(height_data['身長'],[149,155,160,165,170,175,180,185,190,195])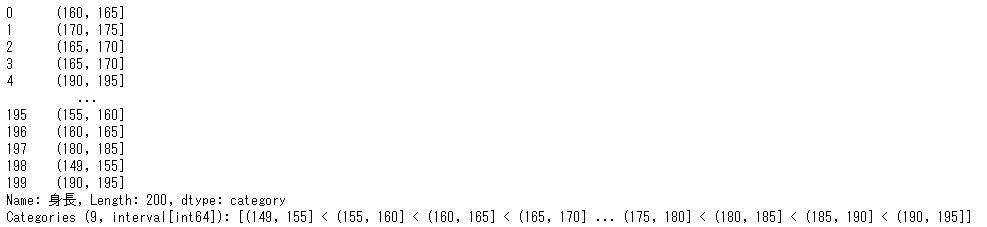
分類したレンジごとの数を知りたければvalue_counts( )を用いて次のようにすることができます。
# 分割後、レンジごとに集計
pd.cut(data,[149,155,160,165,170,175,180,185,190,195]).value_counts()
qcut( )
次にqcut( )による分割です。qcut( )は値の大きさ順にデータを等分してくれます。ここでは、9つに分類することにしましょう。
pd.qcut(height_data['身長'],9)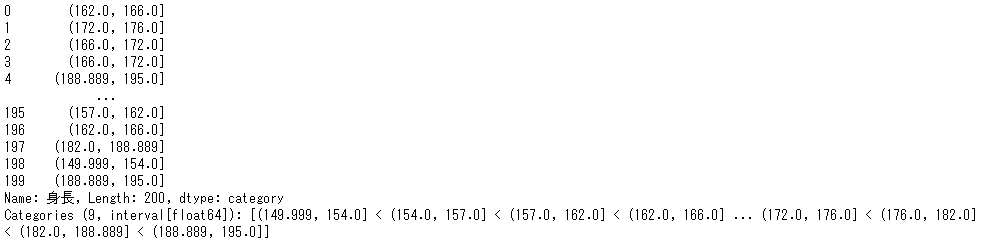
cut( )のときと同様に、レンジごとに集計してみましょう。
pd.qcut(height_data['身長'],9).value_counts()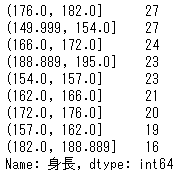
カテゴリ化する
数値を区切ってカテゴリ化するのだから、分割した後の各レンジにラベルを付けておくとわかりやすいです。例えば、身長のデータを分割して、SS, S, M, L, LLにわけてみましょう。
labels=['SS','S','M','L','LL']
pd.cut(height_data['身長'], [149,160,170,180,190,200],labels=labels)
groupbyを使って次のように集計することもできます。
size=pd.cut(height_data['身長'], [149,160,170,180,190,200],labels=labels)
height_data.groupby(size).size()
このように、データフレームの列項目ではなくてもgroupby( )することができます。もちろん、次のようにデータフレームの列項目としてsizeという項目を持たせてもよいでしょう。
height_data['size']=pd.cut(height_data['身長'], [149,160,170,180,190,200],labels=labels)
height_data.groupby('size').size()
もちろん、まったく同じ結果です。
まとめ
いかがでしたか?今回はcut( )、qcut( )によるビン分割を扱いました。連続データをカテゴリ化して扱うことはよくあります。(今回の例のように身長のデータや年齢、体重など)
理解すると、簡単ですね。身に着けておきましょう。
コメント