
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ Numpyの基本を解説しています。過去の記事はこちらからどうぞ。


はじめに
今回はNumpyでよく使う関数についてまとめていくことにします。最大値・最小値・平均値・中央値・標準偏差のような統計量を算出するもののほか、よく使う関数を紹介していきます。関数名も直感的でわかりやすいため、気楽に取り組みましょう。
Numpyでよく使う関数
統計量の算出
始めによく使うものをまとめておきましょう。
では順にみていきましょう。まずサンプルデータを作っておきます。わかりやすいように3×3のndarrayとしましょう。
# サンプルデータの作成
sample_data = np.random.randint(0,100,size=(3,3))
sample_data
このデータを使って各統計量を求める関数を確認していきましょう。まずは最大値からです。
最大値
ndarray.max()は、np.max(ndarray)という書き方もできます。
# 最大値:ndarray.max()
sample_data.max()
# 最大値:np.max(ndarray)
np.max(sample_data)当然、どちらも同じ結果となります。

ndarray.max()に引数に何も指定しないときには、ndarrayの全要素の中から最大のものが抽出されます。最大値ではなく、最大値のindexを返すのがndarray.argmax()です。試してみましょう。
# 最大値のindexを取得
sample_data.argmax()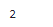
indexが2とわかりました。確かめておきましょう。
# argmax()の結果から最大値を取得
sample_data.flatten()[2]
先ほどと全く同じ結果が得られますね。
次にndarray.max()に引数axisを指定してみましょう。
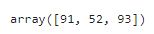
# 最大値:axis=0を指定
sample_data.max(axis=0)axis=0を指定すると列方向の最大値を算出してくれます。

上記のように赤枠内で比較するので、それぞれの枠の最大値が3つ返ってくるわけです。
同様にaxis=1も見ておきましょう。
# 最大値:axis=1を指定
sample_data.max(axis=1)axis=1を指定すると行方向の最大値を算出してくれます。

上記のように赤枠内で比較するので、それぞれの枠の最大値が3つ返ってきます。
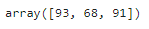
最小値
最大値と同じように扱うことができます。
# 最小値:ndarray.min()
sample_data.min()
# 最小値:np.min(ndarray)
sample_data.min()
最大値の時と同様に全要素の中で最小の抽出してくれます。ndarray.argmin()やaxisの指定も最大値の時と同じなのでここでは割愛します。
平均値
次に平均値です。基本的に使い方はどれも同じなので、どんどん試していきましょう。
# 平均値:ndarray.mean()
sample_data.mean()
# 平均値:np.mean(ndarray)
np.mean(sample_data)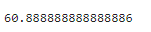
axisを指定すると、列ごと(axis=0)、行ごと(axis=1)の平均値の算出ができます。
# axisを指定して平均値を算出
print('axis=0を指定して平均を算出すると{}'.format(sample_data.mean(axis=0)))
print('axis=1を指定して平均を算出すると{}'.format(sample_data.mean(axis=1)))
中央値
中央値に関しては、np.median(ndarray)という書き方になります。ndarray.median()はエラーとなるので注意してください。
# 中央値:np.median(ndarray)
np.median(sample_data)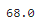
axisについてはその他の統計量と同様のためここでは割愛します。
標準偏差
標準偏差はばらつきを表す指標なので3×3のサンプルデータだとかえってわかりにくいですね。あらたに標準正規分布からサンプルデータを作ることにしましょう。
# 正規分布からサンプルデータを作成
sample_ndarray = np.random.normal(loc=2,scale=0.5,size=(100,100))
sample_ndarray
標準偏差はndarray.std()で求めることができます。
# 標準偏差を算出
sample_ndarray.std()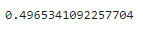
グラフで表してみることにしましょう。100×100の多次元配列を1次元にして分布を見てみましょう。
# ライブラリのインポート
import matplotlib.pyplot as plt
# 標準偏差の算出
std = sample_ndarray.std()
# 可視化
plt.hist(sample_ndarray.flatten(),alpha=0.3)
plt.axvline(x=sample_ndarray.mean(),color='red')
plt.axvline(x=sample_ndarray.mean()-std,color='blue',linestyle='--',alpha=0.5)
plt.axvline(x=sample_ndarray.mean()+std,color='blue',linestyle='--',alpha=0.5)
plt.grid()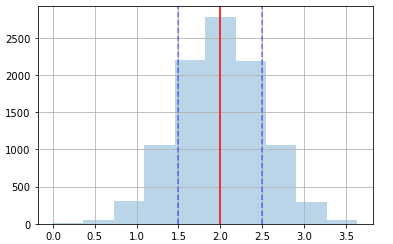
8行目でサンプルデータを一元化したデータのヒストグラムを描いています。赤い線が「平均」、青い線が「平均±標準偏差」となります。この間にデータの約68%が含まれます。実際、そんな感じに見えますね。
その他のよく使う関数
こちらも始めにまとめておきましょう。
こちらも、さくさく試していきましょう。まずは合計からです。こちらは5×5のサンプルデータを使うことにしましょう。
# 合計:ndarray.sum()
sample_data.sum()
# 合計:np.sum(ndarray)
np.sum(sample_data)
axisを指定すれば、もちろん行・列ごとの合計を求めることができます。続いて平方根を確認しましょう。
# 平方根の算出
np.sqrt(sample_data)
np.sqrt()にndarrayを指定すれば、各要素の平方根を求めることができます。続いて指数関数を確認しましょう。
# 指数関数
sample_list = np.linspace(0,10,100)
x = sample_list
y = np.exp(x)
plt.plot(x,y)
plt.grid()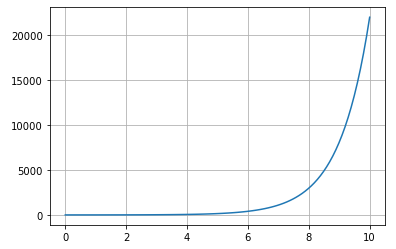
指数関数はnp.exp()です。ここでは2行目でxとするデータの配列を作って、4行目で指数関数を定義しています。最後に絶対値です。
# サンプルデータ
sample = np.arange(10,-5,-2)
sample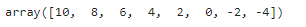
# 絶対値
np.abs(sample)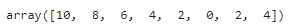
このように負の数を正の数に変換する関数です。
まとめ
今回はNumpyでよく使う統計量を算出する関数、および、その他のよく使う関数を確認しました。「よく使う」関数なので、自然に覚えられると思います。そのため、解説ではなく書式と実際のコードで結果を確認するにとどめました。あとは使いながら覚えていきましょう。
コメント