
はじめに
今回はPandasのデータに関数を適用させる方法を扱います。このblogでもこれまで使っていましたが、一度、整理しておきましょう。扱うのはmap, apply, applymapです。順にみていきましょう。
サンプルデータ
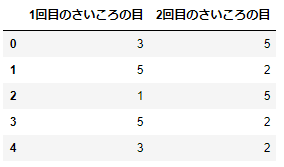
サンプルデータをつくりましょう。6人でさいころを2回ずつ振ったデータを仮定しましょう。
# ライブラリのインポート
import pandas as pd
import numpy as np
pd.options.display.precision=0
# 6人でさいころを2かいずつ振ったときのデータ
sample1=np.random.randint(1,7,5)
sample2=np.random.randint(1,7,5)
df=pd.DataFrame({'1回目のさいころの目':sample1,
'2回目のさいころの目':sample2})
df
データフレームやシリーズに関数を適用する
まず、はじめに整理しておきましょう。map()はSeriesにのみ適用することができ、apply()メソッドはSeriesとDataFrameどちらにも適用できます。applymap()はDataFrameにのみ適用することができます
map()メソッド
さっそくmap()メソッドを試してみましょう。map()メソッドはSeriesに対して適用でき、「各要素」の演算をします。ここではさいころの目によって、「大きい」「普通」「小さい」を判定する関数judge()を作成して「1回目のさいころの目」を取り出したSeriesに対して適用してみましょう。
# 購入回数によって顧客を分類する関数の定義 def judge(x): if x>4: return '大きい' elif x>2: return '普通' else: return '小さい' # Seriesにmap()メソッドを使って関数を適用する df['1回目のさいころの目'].map(judge)

このようにmap()メソッドを使えば、自分で定義した関数もSeriesの各要素に簡単に適用することができます。
apply()メソッド
次にapply()メソッドをみてみましょう。apply()メソッドはDataFrameにもSeriesにも適用できるのでした。まずは、Seriesに適用してみます。先ほどのmap()メソッドをそのままapply()メソッドに置き換えてみましょう。
# Seriesにapply()メソッドを使って関数を適用する df['1回目のさいころの目'].apply(judge)

まったく同じ結果を得ることができました。次にDataFrameに適用した例を見てみましょう。
最大値を求める関数np.maxを適用してみましょう。
# 列に対して演算 df.apply(np.max,axis=0)
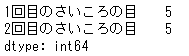
すると、行方向に対する(つまり列に対して)関数が適用され、「1回目のさいころの目」の最大値は5, 「2回目のさいころの目」の最大値は5と計算されました。列方向に(つまり行に対して)処理を行う場合には、axis=1を指定します。
# 行に対して演算 df.apply(np.max,axis=1)

同じように合計を求めることもできます。
# 列ごとの合計 df.apply(np.sum,axis=0)
# 行ごとの合計 df.apply(np.sum,axis=1)

何度か試して慣れてくると簡単ですね。
applymap()メソッド
最後にapplymap()メソッドです。こちらはDataFrameの全要素に対して関数を適用することができます。先に作ったjudgeという関数を適用してみましょう。
df.applymap(judge)
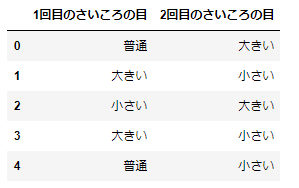
このようにDataFrame全体に対して、各要素への関数の適用ができました。
まとめ
いかがでしたか?整理できましたでしょうか?pandasを使う上では欠かせない方法ですね。よく復習しておいてください。
コメント