
はじめに
今回はLightGBMの実装をしてみます。irisとTitanicという使い慣れた2つのデータセットで試してみましょう。小さなデータセットでは、LightGBMの本来の能力が十分に発揮されないかもしれませんが、まず実装方法を学ぶことにしましょう。
irisで試す
scikitlearnに付属しているデータセットである、irisを使ってLightGBMを試してみましょう。データセットの読み込み方法などについては、前回の投稿を参考にしていただければと思います。

まずはライブラリのインポートとデータの読み込みです。訓練データと検証データを作るところまで書いてしまいましょう。
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データの読み込み
data=load_iris()
# 説明変数と目的変数
X=data.data
y=data.target
# 訓練データ(train)と検証データ(test)にわける
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=1)ハイパーパラメータが多く、悩ましいですね。以下に詳しく書かれていました。

また、こちらも簡潔にまとめられていてわかりやすいです。
https://qiita.com/R1ck29/items/50ba7fa5afa49e334a8f
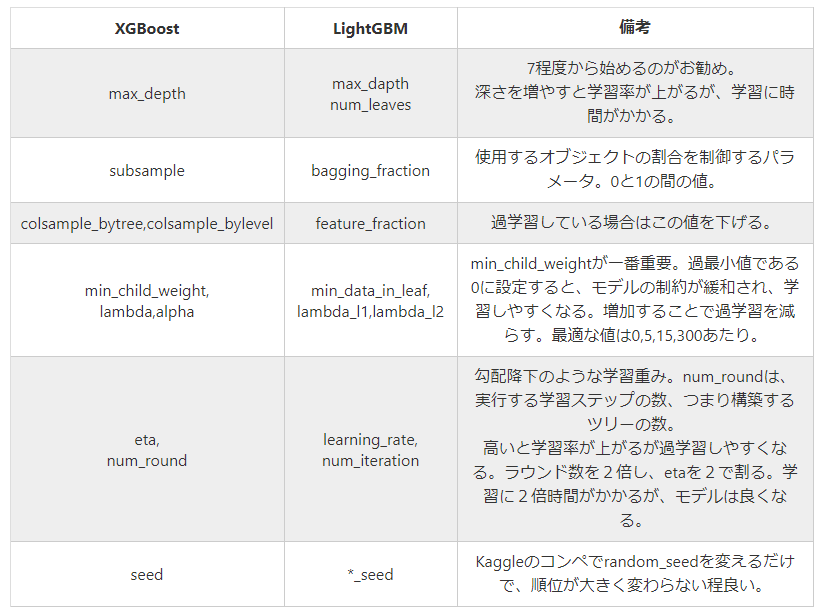
ここでは、「boosting_type」「objective」「max_bin」「learning_rate」「num_leaves」を指定することにしましょう。これらをparamsにまとめて以下のように学習させます。
# パラメータ
params = {'boosting_type':'gbdt',
'objective': 'regression',
'max_bin':300,
'learning_rate':0.05,
'num_leaves':31,
}
# LightGBM用のデータ準備
train_set = lgb.Dataset(X_train, y_train, silent=False)
valid_set = lgb.Dataset(X_test, y_test, silent=False)
# インスタンスの作成と学習
model_lgb = lgb.train(params, train_set = train_set, num_boost_round=100,early_stopping_rounds=50,
verbose_eval=10, valid_sets=valid_set)次に予測と評価です。予測はscikitlearnと同様にpredictでおこなうことができます。
y_pred=model_lgb.predict(X_test,num_iteration=model_lgb.best_iteration)
y_predこれは次のような結果を返します。

最終的には、0,1,2に分類する必要があるので、四捨五入しましょう。その結果を評価します。
# 予測結果を変換
y_pred_fin=[]
for x in y_pred:
y_pred_fin.append(round(x).astype(int))
# 評価
accuracy_score(y_test, y_pred_fin)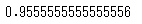
Titanicで試す
Kaggleで公開されている、Titanicのデータ( https://www.kaggle.com/c/titanic/data )を使ってみましょう。ライブラリのインポートとデータの読み込みをまとめておこなっておきましょう。
# ライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score
# 初期設定
sns.set_style('whitegrid',{'linestyle.grid':'--'})
%matplotlib inline
# データの読み込み
train_df=pd.read_csv('C:/python/book\kaggle_start/data/train.csv')
test_df=pd.read_csv('C:/python/book\kaggle_start/data/test.csv')特徴量について
次に特徴量を見ていきましょう。Passenger Idはユニークに採番された番号なので、意味をもちません。そのため、削除してしまいましょう。テストデータのPassenger IDについては、submissionデータ作成のためにインデックス化したデータフレームを作っておきます。
# トレーニングデータ、テストデータからpassenger IDを削除する
train_df.drop(['PassengerId'], axis=1, inplace=True)
test_passenger_ids = test_df.pop('PassengerId')label encodingとしての入力とカテゴリ変数としての入力
label encodingして入力すると、普通の数値型変数と同様に閾値との大小関係で判定されます。カテゴリカル変数として入力すると、marugariさんがブログで紹介しているように変数A (is or is not) category_xで判定されるようです。ただ、カテゴリーに順序性がある場合は、カテゴリカル変数として扱うのはイマイチの場合があるとのこと。2 そのため、カテゴリカル変数でも順序性がある特徴はlabel encodingで、順序性がない特徴はカテゴリカル変数として入力するのが良さそうです。
https://tebasakisan.hatenadiary.com/entry/2019/01/27/222102
このように順序性のあるカテゴリ変数はlabel encodingした方がよい、とのことなので、Embarkedはlabel encodingしてみることにしましょう。
※ .fit()の部分で変換したいデータを選択し、.transform()で実際に数値へ変換します。
# 順序性があるものをlabel encodingする
embarked_encoder = LabelEncoder()
embarked_encoder.fit(train_df['Embarked'].fillna('Null'))特徴量については以下の処理をします。
- Alone:一人であるか否かを表す特徴量
- Embarked:label encoding
- Sex:0 or 1に変換
- ‘Name’, ‘Ticket’, ‘Cabin’は使わない
これらの処理は、train/test両方に施す必要があるので、train_dfとtest_dfをリスト化してforループでそれぞれのdfを取り出して処理するようにしましょう。
df_list = [train_df, test_df]
for df in df_list:
# SibSp(兄弟姉妹、配偶者)Parch(親と子供)が0の人にAloneフラグ
df['Alone'] = (df['SibSp'] == 0) & (df['Parch'] == 0)
# label encodingしたEmbarkedを数値に変換する
df['Embarked'].fillna('Null', inplace=True)
df['Embarked'] = embarked_encoder.transform(df['Embarked'])
# 'Sex'を数値に変換する
df.loc[df['Sex'] == 'female','Sex'] = 0
df.loc[df['Sex'] == 'male','Sex'] = 1
df['Sex'] = df['Sex'].astype('int8')
# 不要な特徴量を取り除く
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)次にトレーニングデータの準備を進めましょう。scikitlearnのtrain_test_splitを使います。
# 目的変数
y = train_df.pop('Survived')
# Hold-Out法でトレーニングデータとテストデータに2:8で分ける
X_train, X_test, y_train, y_test = train_test_split(train_df, y, test_size=0.2, random_state=1)
# Light GBM用のデータを作成(トレーニングデータ)
# カテゴリ変数を明示的に指定する
categorical_features = ['Alone', 'Sex', 'Pclass', 'Embarked']
train_data = lgbm.Dataset(data=X_train, label=y_train, categorical_feature=categorical_features)
# Light GBM用のデータを作成(テストデータ)
test_data = lgbm.Dataset(data=X_test, label=y_test, categorical_feature=categorical_features)データセットを作るときは、lightgbm.Datasetをつかいます。第1引数にはX(特徴量)、第2引数にはy(目的変数)を渡します。カテゴリ変数がある場合は、categorical_featureで指定し、テストデータセットにはreferenceでトレーニングデータセットを指定します。
このあとはハイパーパラメータを決めます。
lgbm_params = {
'boosting': 'gbdt', # default
'application': 'binary', # 二値分類なのでbinaryを選びます
'learning_rate': 0.05, # learning rateは小さめとしておきます
'num_leaves': 41, # num_leavesは少し大きめにする
'metric': 'binary_logloss', # 損失関数
}ここまでできたらいよいよ学習です。
evaluation_results = {}
clf = lgbm.train(train_set=train_data,
params=lgbm_params,
valid_sets=[train_data, test_data],
valid_names=['Train', 'Test'],
evals_result=evaluation_results,
num_boost_round=1000,
early_stopping_rounds=50,
verbose_eval=20
)
optimum_boost_rounds = clf.best_iterationnum_boost_roundは、学習の実行回数です。ここではとりあえず1000回にしておきます。early_stopping_roundsは、early_stoppingの判定基準です。連続何回性能改善しなかった場合に、学習を打ち切るかを決めます。verbose_evalは、学習の過程を何回ごとに表示するかを決めます。ここでは20回ごとに表示することにします。-1とすることで学習の状況を表示しない設定にすることができます。
学習の過程を可視化してみましょう。
fig, axs = plt.subplots(1, 2, figsize=[15, 4])
# Plot the log loss during training
axs[0].plot(evaluation_results['Train']['binary_logloss'], label='Train')
axs[0].plot(evaluation_results['Test']['binary_logloss'], label='Test')
axs[0].set_ylabel('Log loss')
axs[0].set_xlabel('Boosting round')
axs[0].set_title('Training performance')
axs[0].legend()
# Plot feature importance
importances = pd.DataFrame({'features': clf.feature_name(),
'importance': clf.feature_importance()}).sort_values('importance', ascending=False)
axs[1].bar(x=np.arange(len(importances)), height=importances['importance'])
axs[1].set_xticks(np.arange(len(importances)))
axs[1].set_xticklabels(importances['features'])
axs[1].set_ylabel('Feature importance (# times used to split)')
axs[1].set_title('Feature importance')
plt.show()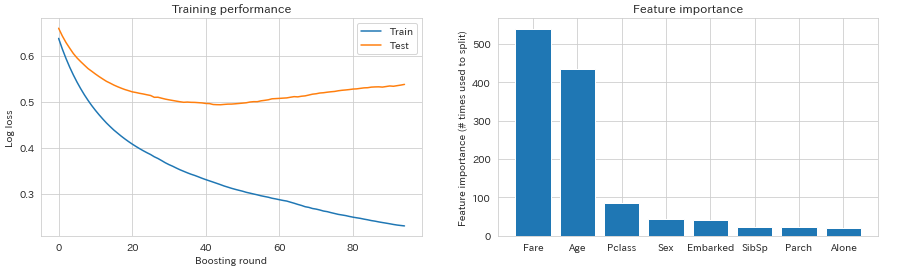
トレーニングデータの損失関数は下がり続けていますが、テストデータでは41付近?で最小となっているように見えます。そこで、num_boost_roundは41に設定して、early_stopping_roundsは10として再学習することにしましょう。すると、以下のようになります。
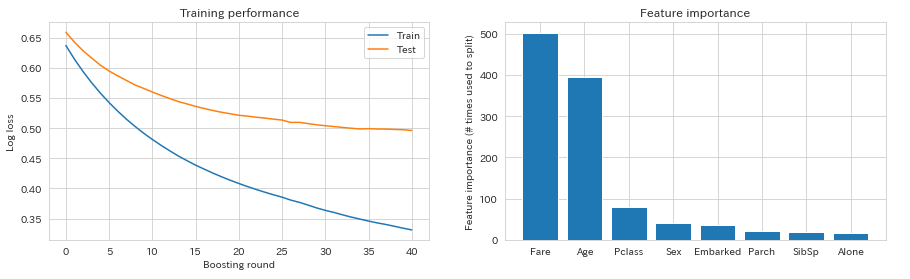
このモデルを評価してみます。
preds = np.round(clf.predict(X_test))
print('Accuracy score = \t {}'.format(accuracy_score(y_test, preds)))
print('Precision score = \t {}'.format(precision_score(y_test, preds)))
print('Recall score = \t {}'.format(recall_score(y_test, preds)))
print('F1 score = \t {}'.format(f1_score(y_test, preds)))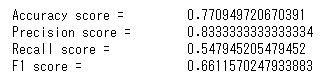
最後に予測です。コード一行ですね。
y_pred = np.round(clf.predict(test_df)).astype(int)ちなみにKaggleへのsubmitデータは次のようにつくるとよいです。
sub_data=pd.read_csv('C:/python/book\kaggle_start/data/gender_submission.csv')
sub_data['Survived']=list(map(int,y_pred))
sub_data.head()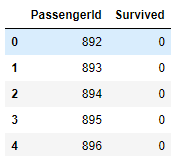
まとめ
いかがでしょうか?LightGBMはパラメータや設定項目が多くて(僕には)難しいですね。でも、数あるアルゴリズムの中でも精度が出やすく、大きなデータに対しても高速で扱える、という利点があるそうなので、使えるようになりたいですね。
▶ LightGBMを利用するときの流れをまとめた記事もあります。

コメント