
▶ 決定木分析を基本から解説した記事もあります。可視化の前に基本から確認したい場合は以下のリンクからどうぞ。

はじめに
今回はツリー系のアルゴリズムである決定木とランダムフォレストを扱います。irisデータの分類問題にチャレンジします。まず、決定木で分類をおこない、次にランダムフォレストで分類して比較してみましょう。また、各特徴量の重要度の可視化も扱います。
データセット
今回扱うデータはirisデータです。これはscikitlearnライブラリに付属しているデータセットです。まずは、必要なライブラリのインポートとデータセットの読み込みをしましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
sns.set_style('whitegrid',{'linestyle.grid':'--'})
%matplotlib inline「from sklearn.datasets import load_iris」の部分で、sklearnに同梱されているデータセットであるirisデータセットを読み込む関数をインポートしています。実際にデータを読み込むには、load_irisi()関数を使います。
data=load_iris()これでデータを読み込むことができます。この読み込んだデータがどういう構造になっているかを見るには、次のようにkeys()を見てみるとある程度予想がつきます。
data.keys()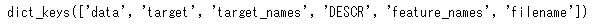
これをみると、「data」が説明変数で「target」が目的変数っぽいです。さらにfeature_namesが説明変数のカラム名で、「target_name」が目的変数の値になっているようです。これで合っているかどうかは実際にデータをみているとよいでしょう。
# data
data.data[0:5]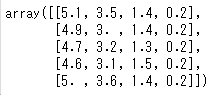
# 特徴量の列名
data.feature_names
# target
data.target[0:5]
# 目的変数の実際の値
data.target_names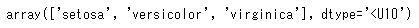
今回は決定木、ランダムフォレストという機械学習アルゴリズムを使うため、説明変数をX、目的変数をyとしておきましょう。これを 訓練データ(train)と検証データ(test)にわけます。
# 説明変数と目的変数
X=data.data
y=data.target
# 訓練データ(train)と検証データ(test)にわける
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=1)決定木
ここからはそれぞれのアルゴリズムをみていきましょう。まずは決定木からです。すでに必要なライブラリはインポートできているので、決定木のインスタンスを作って、学習、予測、評価をしてみましょう。
# モデルの作成
clf = DecisionTreeClassifier(max_depth=3)
# モデルの学習
clf.fit(X_train, y_train)
# 評価
print(clf.score(X_train,y_train))
print(clf.score(X_test,y_test))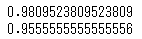
可視化もしておきましょう。dtreevizを使います。
# ライブラリのインポート
from dtreeviz.trees import dtreeviz
viz=dtreeviz(clf,X,y,
feature_names=data.feature_names,
target_name='種類',
class_names=list(data.target_names),
)
display(viz)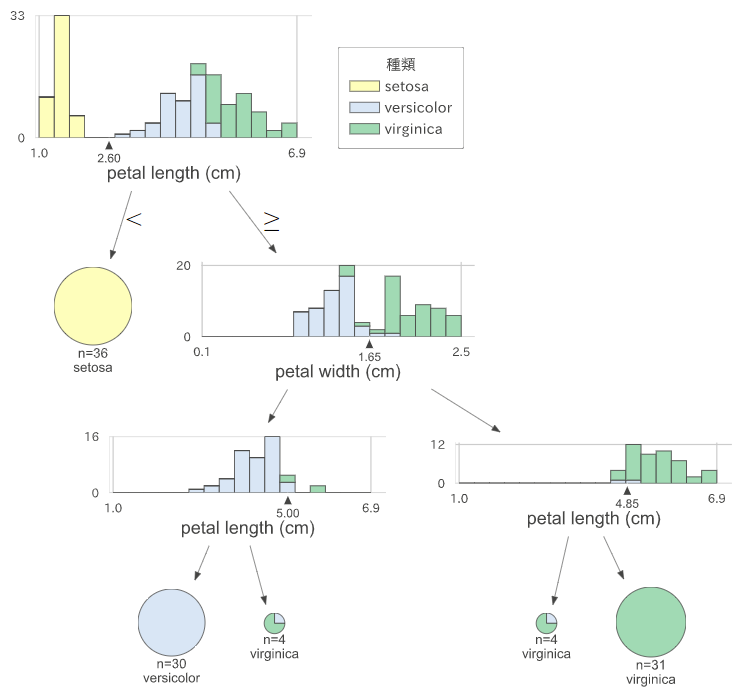
ランダムフォレスト
次にランダムフォレストです。決定木もランダムフォレストもscikitlearnで提供されているので、同じ段取りで扱うことができます。
# モデルの作成
rf = RandomForestClassifier(max_depth=4, random_state=1)
# モデルの学習
rf.fit(X_train, y_train)
# 評価
print(rf.score(X_train,y_train))
print(rf.score(X_test,y_test))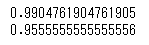
ランダムフォレストも同じように可視化してみましょう。
# 複数の決定木があるため、先頭から2番目の決定木を可視化
estimators = rf.estimators_
viz = dtreeviz(
estimators[1],X,y,
target_name='種類',
feature_names=data.feature_names,
class_names=list(data.target_names),
)
display(viz)
viz.save('randomforest.svg')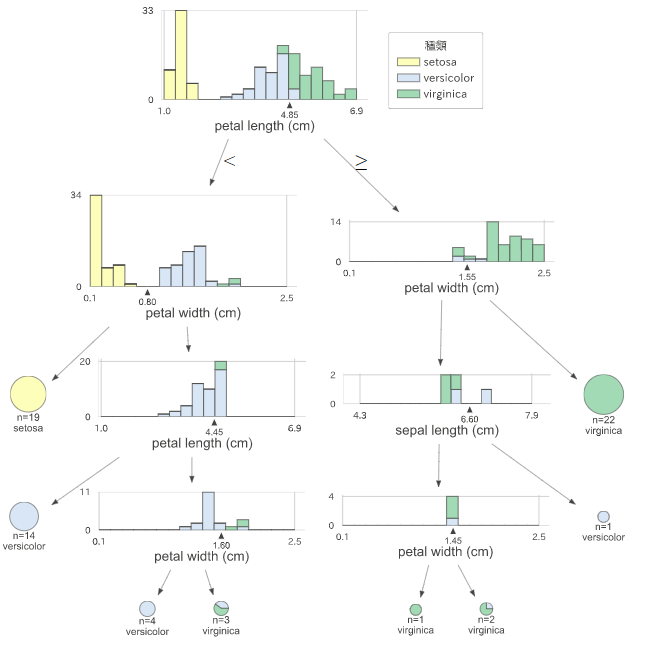
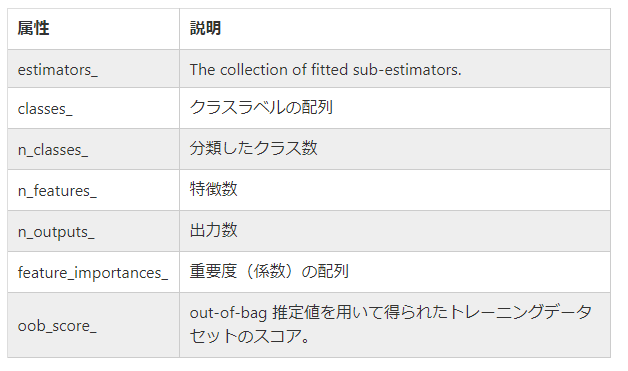
<属性一覧>
https://qiita.com/mshinoda88/items/8bfe0b540b35437296bd
重要度について
決定木もランダムフォレストも重要度の配列は「feature_importances_」という属性からアクセスすることができます。この値と実際の特徴量の名前が入っている「feature_names」を用いてデータフレームを作っておくとわかりやすいでしょう。
# 決定木の説明変数の重要度をデータフレーム化
fea_clf_imp = pd.DataFrame({'imp': clf.feature_importances_, 'col': data.feature_names})
fea_clf_imp = fea_clf_imp.sort_values(by='imp', ascending=False)
# 決定木の重要度を可視化
plt.figure(figsize=(10, 7))
sns.barplot('imp','col',data=fea_clf_imp,orient='h')
plt.title('Decision Tree - Feature Importance',fontsize=28)
plt.ylabel('Features',fontsize=18)
plt.xlabel('Importance',fontsize=18)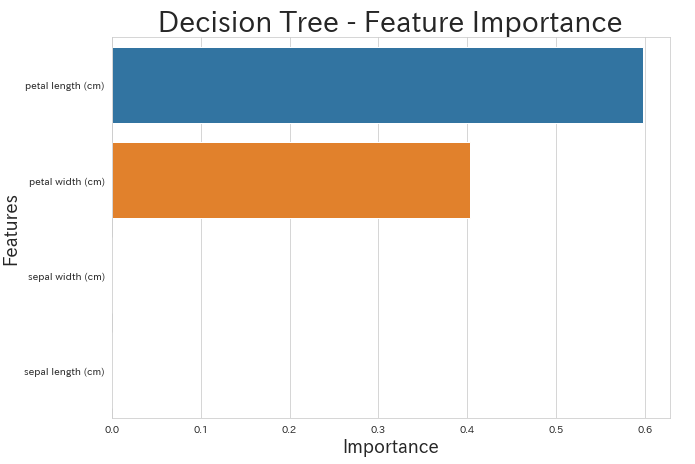
# ランダムフォレストの説明変数の重要度をデータフレーム化
fea_rf_imp = pd.DataFrame({'imp': rf.feature_importances_, 'col': data.feature_names})
fea_rf_imp = fea_rf_imp.sort_values(by='imp', ascending=False)
# ランダムフォレストの重要度を可視化
plt.figure(figsize=(10, 7))
sns.barplot('imp','col',data=fea_rf_imp,orient='h')
plt.title('Random Forest - Feature Importance',fontsize=28)
plt.ylabel('Features',fontsize=18)
plt.xlabel('Importance',fontsize=18)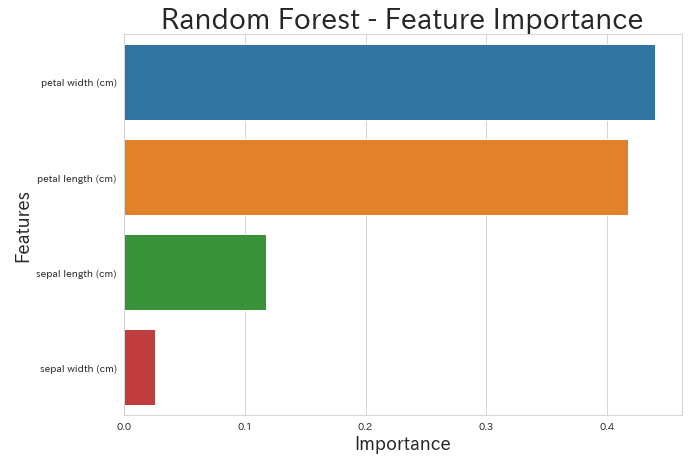
こうしてみると、決定木では重要となれる特徴量は2つで、「petal length」「petal width」の順です。そのため、分類の過程を可視化した時もこの2つの特徴量が使われ、また、一番重要な「petal length」が一番始めの条件になっています。
一方で、ランダムフォレストではその他の特徴量も利用した分類となっています。分類の過程については、ランダムフォレストで作られる複数の決定木の中で1つを代表して可視化しただけなので、ランダムフォレストの場合には必ずしも対応しません。
まとめ
今回は決定木とランダムフォレストを扱いました。説明力が高いといわれるアルゴリズムなので、分類の過程や重要な特徴量について可視化までおこないました。実務では「説明力」は重要ですよね。是非、試してみてください。
▶ 可視化したあと、どのように解釈をするかを解説した記事もあります。

コメント
とても参考になりました。
私の環境でも実行できました。
これはいいですね!!
※# 決定木の説明変数の重要度をデータフレーム化の
“fea_clf_imp = fea_imp.sort_values(by=’imp’, ascending=False)””
は、
“fea_clf_imp = fea_clf‗imp.sort_values(by=’imp’, ascending=False)””
ではないかと思います。
コメント&間違いのご指摘ありがとうございます。
早速、該当箇所の修正をおこないました。