
はじめに
今回はk-分割交差検証を扱います。k-分割交差検証は、データをk個に分割して、n個を訓練用にk-n個をテスト用に使うということを、分けられたk個のデータが必ず1回はテスト用に使われるように繰り返します。こうすることで、過学習を防ぎ汎化性能を評価することができます。Pythonではsklearnという機械学習用ライブラリを用いることで簡単に交差検証を使ってモデルを検証することができます。
サンプルデータ
今回はirisのデータを使うことにしましょう。
# ライブラリのインポート
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
# データの読み込み
iris=load_iris()
X,Y=iris.data,iris.target
# 行・列数の確認
print(X.shape)
print(Y.shape)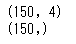
k-分割交差検証
KFoldを使う
まずはKFoldを使ってデータ分割をおこない、上記に記載した訓練用/テスト用に使う組み合わせを変えて、モデルを構築して平均をとってみましょう。
# ライブラリのインポート
from sklearn.model_selection import KFold
# データ
kf=KFold(n_splits=2,shuffle=True)
scores=[]
for train_id,test_id in kf.split(X):
x=X[train_id]
y=Y[train_id]
clf=DecisionTreeClassifier(max_depth=3,random_state=42)
clf.fit(x,y)
pred_y=clf.predict(X[test_id])
score=accuracy_score(Y[test_id],pred_y)
scores.append(score)
scores=np.array(scores)
print(scores.mean())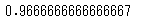
精度96%となりました。この方法でも十分簡単ですが、sklearnのcross_val_scoreを使うともっと簡単に評価することができます。
cross_val_scoreを使う
from sklearn.model_selection import cross_val_score
clf_cross=DecisionTreeClassifier(max_depth=3,random_state=42)
scores=cross_val_score(clf_cross,x,y,cv=10)
print(scores.mean())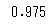
汎化性能を評価する
k-分割交差検証の方法がわかったので、実際に確認してみましょう。たとえば、ここで用いたirisのデータを、ロジスティック回帰と決定木でモデル構築してみます。これを交差検証しないで評価した場合と交差検証した場合の評価結果を比較してみましょう。
交差検証をしないで評価
まずはデータを訓練用とテスト用に分割しておきましょう。
# データの分割
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.5,random_state=0)次にここでは、ロジスティック回帰と決定木のモデルを作成して評価してみます。
# ロジスティック回帰
# インスタンスの作成
lr=LogisticRegression(random_state=0)
# 学習
lr.fit(X_train,y_train)
# 予測
y_pred=clf.predict(X_test)
# 評価
print(accuracy_score(y_test,y_pred))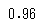
次に決定木です。
# 決定木
clf=DecisionTreeClassifier(max_depth=3,random_state=0)
# 学習
clf.fit(X_train,y_train)
# 予測
y_pred=clf.predict(X_test)
# 評価
print(accuracy_score(y_test,y_pred))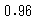
ロジスティック回帰でも決定木でも正解率は0.96となりました。次に交差検証で評価してみましょう。
交差検証をして評価
まずはロジスティック回帰からです。
# ロジスティック回帰
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression(random_state=0,max_iter=200)
scores=cross_val_score(lr,x,y,cv=10)
print(scores.mean())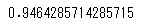
交差検証で評価すると0.94という結果となりました。決定木についてもみておきましょう。
# 決定木
from sklearn.model_selection import cross_val_score
clf_cross=DecisionTreeClassifier(max_depth=3,random_state=0)
scores=cross_val_score(clf_cross,x,y,cv=10)
print(scores.mean())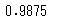
結果は0.98となりました。こうしてみると、交差検証せずに評価した場合はどちらのモデルも0.96で同等ですが、交差検証で評価すると決定木の方が汎化性能が高い、といえます。
まとめ
いかがでしたか?モデルは未知の値を予測するのが目的ですから、汎化性能は重要な指標となります。是非、この考え方を身に着けておきましょう。
▶ 交差検証を取り入れるとLightGBMの汎化性能をあげることができます。こちらの記事もいっしょにいかがですか?


コメント
3.1 KFoldを使う に書かれているコードを回すとエラーが出るのですが
どうすればよいでしょうか?
以下のエラーが出ます
index 75 is out of bounds for axis 0 with size 75
こんにちは、コメントありがとうございます。
うまく動かなかったようで申し訳ありません。
まず「2.サンプルデータ」で「Y(大文字)」とするべきところを「y(小文字)」で記載していました。
そもそもこのままだと動かないので、直接の原因ではないかもしれませんが、訂正させていただきます。
エラーに次いで須賀、
index 75 is out of bounds for axis 0 with size 75
というエラーは、配列に対して範囲外の要素をしている、というエラーです。
x,yの要素数はそれぞれ75ずつあるかを一度、ご確認いただけますでしょうか?