
はじめに
はじめて扱うデータや自分の複数のテーブルを組み合わせた場合は、重複データの確認をおこなうようにしましょう。重複データが生じる要因は様々でです。単純にデータが重複している場合もあれば、人的ミスによる場合もあります。pandasのシリーズとデータフレームではduplicatedメソッドを使うと簡単に検知することができます。
サンプルデータの作成
まず、リストのリストを作り、これをもとにデータフレームを作りましょう。次のようにpd.DataFrameの第一引数にリストのリストを指定して、indexとcolumnsを指定すれば簡単にデータフレームを作ることができます。
tmp=[[1,2,3],
[1,2,3],
[1,2,3]]
df=pd.DataFrame(tmp,index=list('abc'),columns=list('xyz'))
df
重複データの検知
作成したサンプルデータはご覧のように重複したデータとなっています。duplicatedメソッドを使って重複データがどのように検出されるかを見ていきましょう。
引数keep
基本的にduplicatedメソッドは重複した行をTrue、それ以外をFalseのbool型の値を持つシリーズを返します。シリーズのインデックスラベルは元のデータフレームのインデックスラベルが付与されます。重複の検出方法をkeep引数により指定することができます。初期値はfirstでこれは最初の重複データ以外の重複をTrueとします。
df.duplicated()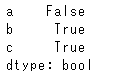
このデータフレームは3つのレコードがあり、すべて重複しています。duplicated()で検出すると、確かにひとつめがFalse、続く2つ目、3つ目はTrueとなっています。keepという引数はlastを指定することもできます。この動きも見ておきましょう。
df.duplicated(keep='last')
今度は1,2番目のレコードがTrueで3番目がFalseとなりました。これは重複データの最後をFalseに、それ以外をTrueにする設定となります。また、keep=Falseとなるすと、重複データをすべrてTrueで返します。
引数subset
subset引数は指定した列の値のみを考慮して重複データの検出をおこないます。ここではkeep引数にはFalseを指定して重複データはすべてTrueとなるように設定しておきましょう。サンプルデータを少し書き換えておきましょう。
# サンプルデータの書き換え
df.loc['c','y']=5
df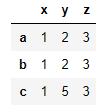
このデータに対してsubsetでxを指定した場合とyを指定した場合を見ておきましょう。
df.duplicated(keep=False,subset='x')
この場合はx列のみを重複しているかどうか判定しています。結果的にすべて同じ値なのですべてTrueを返します。次にy列で判定してみましょう。
df.duplicated(keep=False,subset='y')
indexがcのレコードのみ5になっているのでFalseとなります。subsetには複数のカラムを指定することもできます。是非、挙動を確かめてみてください。
重複データの削除
重複したデータを削除するべきかどうかは慎重に考えるべきですが、ここでは削除する方法を扱っておきましょう。ここでも先ほどのサンプルデータを使います。

重複データの削除には、drop_duplicates()メソッドを使います。このdrop_duplicates()メソッドにもkeep引数が用意されています。first, last, Falseを指定することができます。このメソッドは重複データを削除したデータフレームを戻します。今回のサンプルではa行とb行が重複しています。keep=’first’を指定した場合は、a列を残し(keep)、b列が削除されます。
df.drop_duplicates(keep='first')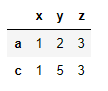
まとめ
いかがでしょうか?これらは慣れれば簡単ですね。subsetに複数の列を指定した場合はあえて扱わなかったので、是非、練習としてやってみてください。この操作は実務でもよく使う操作なので、確実に扱えるようにしておきましょう。
コメント