
はじめに
データ分析では、グループ化をして平均値や中央値などの統計量を求めることがあります。これはGroupByオブジェクトのaggメソッドを使います。さらに、グループ化されたデータに対して変形する操作も少なくありません。今回はこの変形処理をおこなうtransformを扱います。
サンプルデータ作成
seabornのデータセットであるtipsデータセットから一部を抽出して加工したものをサンプルデータとして使うことにしましょう。
import pandas as pd
import seaborn as sns
tips=sns.load_dataset('tips')
tips=tips.head()
tips['name']=['A','B','C','D','E']
tips=tips[['name','sex','total_bill']]
tips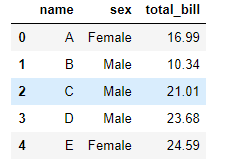
transformメソッド
ここではサンプルデータを使って動きを見ていきます。まずは、サンプルデータを’sex’をキーとして平均値をもとめてみます。
tips.groupby('sex').agg('mean')
transformメソッドは指定する関数の戻しがグループ化されたデータと同じサイズの場合、各グループの値をブロードキャストして元のデータフレームと同等のサイズを戻します。先の例では、aggメソッドはグループ化された’sex’ごとの平均値を戻しましたが、transformメソッドは’sex’ごとの平均値をブロードキャストして、元のデータフレームと同等のサイズを戻します。
tips.groupby('sex').transform('mean')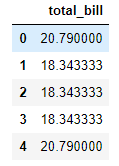
混同しやすいですが、transformメソッドへ指定する関数が元データフレームと同等のサイズを戻す場合は、それぞれの値に対して処理がされています。少しわかりやすくしましょう。
tips2=tips.copy()
tips2['性別平均']=tips.groupby('sex').transform('mean')
tips2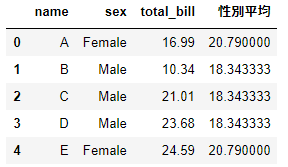
このように’sex’の値Male/Femaleごとの平均が結果が、各行に表示されています。Femalであるindexが0と4、Maleであるindexが1,2,3のものはtransformで計算した性別平均に同じ値が格納されています。
transformメソッドをつかえば、次のような全体の支払額に占める男女の割合(pct)も簡単に求めることができます。
tips['pct']=tips.groupby('sex').transform(lambda x:x/x.sum())
tips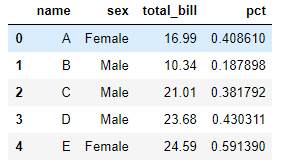
まとめ
transformメソッドは元データフレームと同等のサイズを戻すことから、より柔軟なグループ化したデータの処理がおこなえます。 便利ですね!
コメント
小生、初学者です。参考にさせて頂いております。
エラーが出ます。
tips[‘pct’]=tips.groupby(‘sex’).transform(lambda x:x/x.sum())
この部分、
tips[‘pct’]=tips.groupby(‘sex’)[‘total_bill’].transform(lambda x:x/x.sum())
ではないでしょうか?
こんにちは。
コメントありがとうございます。
こちらの環境で試すと問題なく動作するのですが、
どんなエラーが表示されますか?
もしかしたら、このコードの前に
tips2=tips.copy()
tips2[‘性別平均’]=tips.groupby(‘sex’).transform(‘mean’)
としているのですが、この「tips2」に対して実行していませんでしょうか?
また、transformの返り値を代入せずに以下のようにすると、
どのような結果となりますでしょうか?
tips.groupby(‘sex’).transform(lambda x:x/x.sum())
rakuda様
ご指摘の通りでした。tips2に対してやっておりました。
typs2では、”total_bill”,”性別平均”のふたつがありますので、それが問題でした。
理解しました。
ありがとうございました。
こんにちは。
返信ありがとうございます。
このページがわかりにくかったですね。
申し訳ありません。
でも、解決してよかったです。
また何かございましたらコメントいただけると助かります。
よろしくお願いいたします。