
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ Python初学者向けにデータ分析に関する記事を書いています

はじめに
今回はもらったデータが行・列が入れ替わっていた場合の対処方法を基本から解説します。手元のデータが行・列が逆なんだよなぁ、といった経験はないですか?そのまま不通に読み込んで転置してもうまくいかない場合の対処方法を解説します。
行と列が入れ替わったデータの取り扱い
どうぶつの「なまえ」「どうぶつえん」「ねんれい」のデータを扱うことにしましょう。下のようなデータです。

このデータが行と列が入れ替わった上でのcsvで提供された場合どのように扱ったらよいでしょうか?このケースの対処方法を基本から解説します。
普通に読み込むと・・・
オプションを指定せずに読み込むと次のようになります。
# ライブラリのインポート
import pandas as pd
# データの読み込み
df = pd.read_csv('animal.csv')
このままでは「転置」してもうまくいきません。
# データフレームを転置する
df.T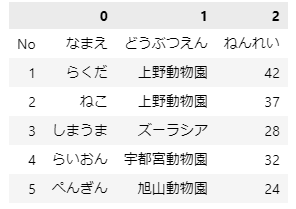
本来、列名としたい部分が1行目に来てしまってますね。
1列目をインデックスに設定する
転置前のデータを見ると、1列目に本来ヘッダーとしたい項目が並んでいます。そのため、1列目をインデックスに指定して、その後に転置すればうまくいきそうです。やってみましょう。
# 1列目をインデックスに設定する
df = df.set_index('No')
df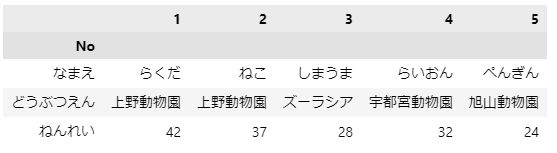
この形であれば転置すればうまくいきそうですね。確認しておきましょう。
# データフレームを転置する
df.T
うまくいきました。次にはじめからインデックスを指定して読み込む方法をみていきましょう。
インデックスを指定して読み込む
「そのまま読み込んだ場合」のデータを見ると、列名にしたいデータが1列目にあります。転置で行と列は簡単に入れ替えることができるので、1列目をインデックスとすることができれば、その後に転置すればうまくいきそうです。
データの読み込み時に1列目をインデックスとして読み込んでみましょう。
# インデックスとする列を指定してデータを読み込む
df2 = pd.read_csv('animal.csv', index_col=0)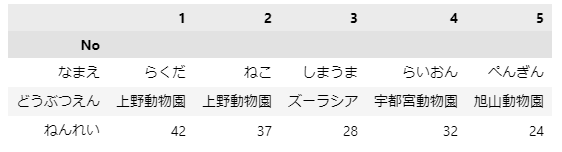
うまくいきました。これだと転置するだけでレコードが縦に並んでデータにすることができますね。確認しておきましょう。
# データフレームを転置する
df.T
まとめ
今回は行と列が入れ替わったデータが与えられた場合の対処方法について解説しました。pandasでは転置は簡単にできるので、転置前にインデックスを設定しておくことに気を付ければよいです。
そのためには、set_index()を使う方法と、そもそもデータの読み込み時にindex_colでインデックスにする列番号を指定するやり方があるのでした。理解すれば簡単ですね!
コメント