
▶ データ分析を基本から学びたい場合は、以下の記事もご覧ください。

- Pythonによるデータ分析を学び始めたばかりでpandasライブラリの基本を学びたい方
- pandasライブラリのデータ構造の理解がまだあやふやな方
- まずはpandasライブラリを使う上で知っておきたい「データ構造の基本」を速習したい方
はじめに
Pythonでデータ分析をおこなうのであれば、pandasは必須のライブラリとなります。今回はpandasのデータ構造を学びましょう。pandasのデータ構造としては、Serires、DataFrame、Indexがありますが、今回はSeriresとDataFrameの基本を解説していきます。
pandasデータ構造
pythonでpandasライブラリを利用するときには、importする必要があります。import時にpdという別名でインポートすることが多いです。次のようにします。
# ライブラリのインポート
import pandas as pdSeriesオブジェクト
pandasのSeriesオブジェクトは、見出し(index)を持ったリストのイメージを持つとわかりやすいでしょう。リストはただ単に、データを順番に並べたものであったのに対して、Seriesでは見出し(index)があります。これは数字である必要はなく、文字列でも可能です。
例を見ていきましょう。
Seriesの作成
いろんな作り方がありますが、基本は次のような形となります。
pd.Series(data, index=index)では、dataとして[10,2,5,6,2]を indexとして[‘a’, ‘b’, ‘c’, ‘d’, ‘e’]を与えてみましょう。
# dataとindexと低地
data=[10,2,5,6,2]
index=['a','b','c','d','e']
# Seriesを作成
pd.Series(data,index=index)indexを指定しないと数字が自動的に振られます。そのためか、「Seriesがindexを持つことを知らなかった」「Seriesのindexは数字だけだと思っていた」という声をよく聞きます。
そこで今回は、indexをはじめから文字列として与える例としました。上のコードを実行すると以下のようになります。
a 10
b 2
c 5
d 6
e 2
dtype: int64今度はindexを指定しないでSeriesを作ってみます。
pd.Series(data)実はこれでもSeriesを作ることができます。indexは指定しない場合は0から自動的に採番されます。結果をみておきましょう。
0 10
1 2
2 5
3 6
4 2
dtype: int64index属性とvalues属性
ここまで見てきたように、Seriesは値とindexを持ちます。これらはvalues属性とindex属性でアクセスることができます。
Seriesオブジェクトをsample_seriesという変数に格納して、index属性とvalues属性にアクセスしてみましょう。
# Seriesを作成
sample_series=pd.Series(data,index=index)
sample_series先ほども確認しましたがこの出力は次のようになります。
a 10
b 2
c 5
d 6
e 2
dtype: int64このsample_seriesのindex属性、values属性を見てみましょう。
print(sample_series.index)
print(sample_series.values)この出力結果は以下のようになります。
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
[10 2 5 6 2]indexを文字列で与えているときは分かりやすいですね。では、先ほどのindexを与えなかったときの例でも確認しておきましょう。
# Seriesを作成
sample2_series=pd.Series(data)
sample2_seriesこの出力は以下のようになりますね。
0 10
1 2
2 5
3 6
4 2
dtype: int64では、このsample2_seriesのindex属性とvalues属性を見てみましょう。
print(sample2_series.index)
print(sample2_series.values)この結果は次のようになります。
RangeIndex(start=0, stop=5, step=1)
[10 2 5 6 2]values属性の方はこれまでと同じ結果で問題ないですね。index属性は、RangeIndexとなっていますね。これを少し補足しておきます。
DataFrameオブジェクト
DataFrameオブジェクトは、表形式のデータです。行方向の見出し(index)と列方向の見出し(columns)を持っています。
DataFrameの作成
DataFrameの作成はいくつか方法があるので、はじめは少し混乱するかもしれません。ただ、DataFrameが表形式のデータで、行方向・列方向に見出しを持つ構造であることを押さえておけば、大丈夫です。どのDataFrame作成方法もこの構造を意識すると、直観的に理解できるかと思います。
Seriesオブジェクトから作成する
DataFrameをSeriesの集まりとして考えます。Seriesには既に見出し(index)が設定されていますので、DataFrameとして列方向の見出し(columns)を設定する必要があります。そのため、SeriesオブジェクトからDataFrameを作る場合は、次のような形となります。
pd.DataFrame(data_series, columns=columns)既にデータがあり、行方向の見出し(index)が設定されているSeriesに対して、列方向の見出し(columns)を指定するだけ、というわけです。この例をみておきましょう。先ほど作成した「sample_series」を使いましょう。
pd.DataFrame(sample_series,columns=['年齢'])この結果は、先ほど作成した「sample_series」の列方向ラベルに「年齢」が付いたものなので、次のようになります。

辞書のリストから作成する
次に辞書のリストからDataFrameを作成する例をみていきましょう。辞書では既に列方向ラベルがついているので、辞書のリストにそのまま「pd.DataFrame()」とするだけでDataFrameを作成することができます。
# 辞書の作成
dic1={'名前':'らくだ','出身':'神奈川県','購入金額':4200}
dic2={'名前':'ねこ','出身':'神奈川県','購入金額':3800}
dic3={'名前':'しまうま','出身':'京都府','購入金額':2400}
dic4={'名前':'ぱんだ','出身':'東京都','購入金額':1800}
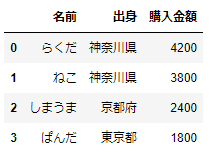
# 辞書のリストからDataFrameを作成
pd.DataFrame([dic1,dic2,dic3,dic4])これを実行すると、次のような結果となります。
Seriesの辞書から作成する
次にSeriesから作る方法です。Seriesは既に行方向の見出し(index)をもったデータなので、複数のSeriesの辞書にすることで列方向の見出し(columns)も設定できますね。これも一つ例をみておきましょう。
# Seriesを作る
ser1=pd.Series(['らくだ','ねこ','しまうま','ぱんだ'])
ser2=pd.Series(['神奈川県','神奈川県','京都府','東京都'])
ser3=pd.Series([4200,3800,2400,1800])
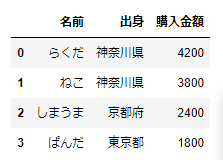
# Seriesの辞書からDataFrameを作成
pd.DataFrame({'名前':ser1,'出身':ser2,'購入金額':ser3})これも先ほどと同様の結果となります。辞書のリストはレコードを行方向に結合したイメージ、Seriesの辞書は、Seriesを列方向に結合したイメージとなります。
リストのリストから作成する
もっといろんなパターンがあるのですが、ここでは「リストのリスト」からDataFrameを作る方法の紹介で最後にしておきましょう。これは「辞書のリスト」から作るパターンと似ていて、レコードを行方向に結合するイメージです。但し、リストには行方向の見出し(index)がないので、index, columnsの両方を指定する必要があります。
例を見ておきましょう。
# リストをつくる
list1=['らくだ','神奈川県',4200]
list2=['ねこ','神奈川県',3800]
list3=['しまうま','京都府',2400]
list4=['ぱんだ','東京都',1800]
# リストのリストからDataFrameをつくる
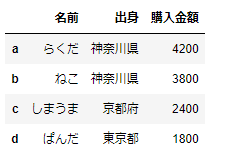
pd.DataFrame([list1,list2,list3,list4],index=['a','b','c','d'],columns=['名前','出身','購入金額'])今回、indexはあえて[‘a’, ‘b’, ‘c’, ‘d’]としています。この結果は次のようになります。
これまで見てきたように、indexやcolumnsの指定は省略することができます。ここでは、indexの指定を省略してみることにしましょう。
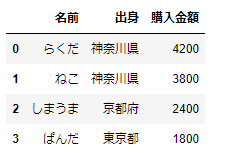
# リストのリストからDataFrameをつくる
pd.DataFrame([list1,list2,list3,list4],columns=['名前','出身','購入金額'])この結果は次のようになります。先ほどはindexを[‘a’, ‘b’, ‘c’, ‘d’]に指定していましたが、今回はindexを指定しなかったので、自動的に0,1,2,3が設定されていますね。
まとめ
いかがでしたか?今回はpandasライブラリのデータ構造、SeriesとDataFrameの基本を学びました。以下にまとめておきましょう。
▶ データ分析を基本から学びたい方は、以下の記事もご覧ください。
コメント