
はじめに
JSONはデータの受け渡しに広く使われるデータ形式です。機械学習でもWebAPIからデータを取得した場合は、この形式になっていることが多いため、目に触れる機会も多いと思います。今回は、このJSON形式を扱います。
サンプルデータ
今回もscikitlearnのirisデータセットを使います。
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_iris
# データの読み込み
data=load_iris()
data.keys()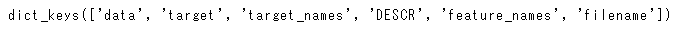
df=pd.DataFrame(data.data,columns=data.feature_names).head()
df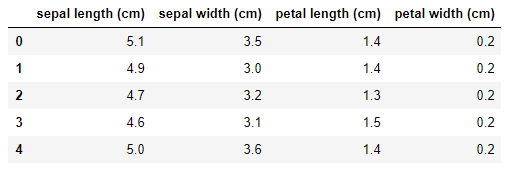
JSONファイルへの書き出し
データフレームをJSONフォーマットへ変換する場合は、to_jsonメソッドを使います。 to_jsonメソッドには第1引数にファイルパスを指定してJSONフォーマットのファイルとして書き出すことができます。
df.to_json('test.json')第一引数に何も指定しなかった場合、データフレームがJSON文字列へ変換されます。
df.to_json()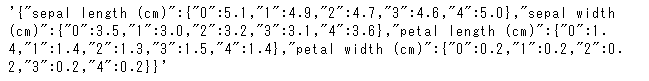
to_jsonメソッドはorient引数(初期値columns)があり、データフレームからJSON文字列へ変換するフォーマットを指定できます。orient引数へ指定可能な値は次の表のようになります。
| 値 | フォーマット |
| split | ディクショナリと類似したフォーマット。 {インデックス -> [インデックス], カラム -> [カラム], データ -> [値] } |
| records | リストと類似したフォーマット。 [{カラム -> 値}, …, {カラム -> 値}] |
| index | ディクショナリと類似したフォーマット。 {インデックス -> {カラム -> 値}} |
| columns | ディクショナリと類似したフォーマット。 {カラム -> {インデックス -> 値}} |
| values | データフレームの値の配列 |
| table | ディクショナリと類似したフォーマット。データのスキーマの情報を有する。データはorient=’records’のフォーマットに準ずる。 {‘schema’:{schema}, ‘データ’:{データ}} |
df.to_json(orient='table')
JSONファイルの読み込み
JSON文字列をpandasのオブジェクトとして読み込む場合はread_json関数を使います。第一引数でファイルパスあるいは、JSON文字列を指定します。read_json関数のtyp引数により、戻すpandasのオブジェクトを指定することができます。初期値はframeでJSON文字列をデータフレームへ変換して戻します。
pd.read_json('test.json',typ='frame')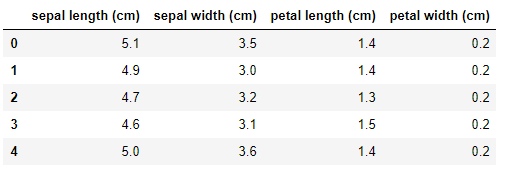
JSONの書き出しで使ったto_jsonメソッドと同様、read_json関数にもorient引数が用意されています。orient引数の初期値はtyp引数の値により異なります。JSON文字からの書き出しがデータフレームの場合(typ=frame)、orient引数の初期値はcolumnsです。
read_json関数には読み込み時にデータ型の制御をおこなう引数も用意されています。dtype引数が初期値Trueの場合、データ読み込み時にデータ型の推測をおこないます。また、カラムラベルをキー、データ型をバリューとして持つディクショナリを指定した場合、読み込み時に明示的にカラムのデータ型を指定できます。
まとめ
いかがでしょうか?私はJSONってなんだかよくわからなくてとっつきにくい!って思ってました。これまで扱ったことのある身近なirisデータで確認してみると、理解できたのではないでしょうか?
コメント