
はじめに
Pandasでは、欠損値NaNがあるデータを扱っても基本的にはエラーとはなりませんが、処理結果がNaNになることが多いです。一部の関数では、NaNを除いて処理をおこない、結果を返してくれるものもありますが、基本的には処理前に欠損値の処理をしておくほうがよいでしょう。今回は、この欠損値の処理について扱います。
欠損値の処理方法
欠損値の処理方法は、大きくわけて以下の2通りとなる。
- 欠損値のあるレコードデータを削除する
- 欠損値を埋める(補完する)
以降、それぞれについてみていく。
データの準備
まず、欠損値のあるサンプルデータを作成する。以下のコードで作成できます。
import numpy as np
import pandas as pd
sample_df=pd.DataFrame(np.random.rand(10,4))
# 一部のデータをわざと欠損させます
sample_df.iloc[1,2]=np.nan
sample_df.iloc[1,3]=np.nan
sample_df.iloc[7:,1]=np.nan
sample_df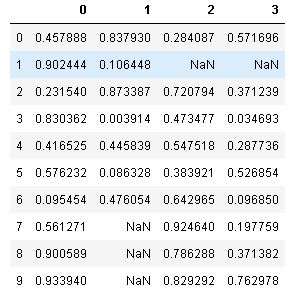
欠損値の削除
欠損値を削除するのは、簡単でdropna()を使うとよい。欠損のある行をまるごと削除するには、データフレームに対してdropna()を適用するだけでよい。
sample_df.dropna()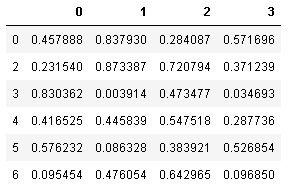
dropna()では、defaultでは欠損値のある行を丸ごと削除します。これに対して、 利用可能なデータをできるだけで使うという考え方もあります。欠損の少ない列だけを用いて、対象とした列に欠損がある場合は行ごと削除することもできます。次のように、dropna()にsubsetオプションを設定します。
sample_df.drop(1,axis=1,inplace=True)
sample_df.dropna(subset=[0,2,3])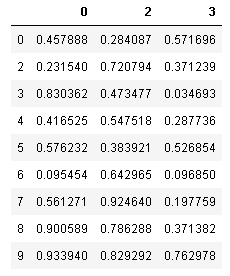
欠損値を埋める
欠損値を埋めるには、fillna()を使います。ここに、補完する定数や平均値、中央値などの集計値を指定することで、欠損を埋めることができます。
# 平均値で欠損値を埋める
sample_df.fillna(sample_df.mean())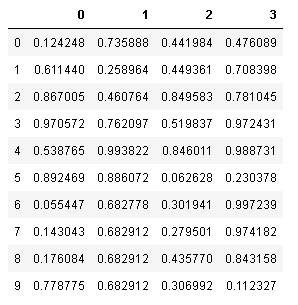
このとき平均値は、列ごとに計算されて、各列の欠損値にこの平均値が適用されます。
定数や集計値ではなく前の値で埋める、という場合は、methodオプションで’ffill’を指定します。
sample_df.fillna(method='ffill')
まとめ
今回は欠損値の取り扱いを学びました。基本的に、欠損値は計算前に処理をする、その処理方法は、削除するか、欠損を埋める、の2つでしたね。実データにはほとんどの場合、欠損値があります。確実に処理できるようにしておきましょう。
コメント