
はじめに
今回はmap()を扱います。普段、apply()の利用で事足りているのですが、一度、map()についても整理しておきましょう。mapにしてできない処理、として辞書を使った変換があります。これは便利なので是非、活用しましょう。
ところで、map()って、はじめ戸惑いませんでした?apply()と何が違うのだろう?あれ、なんか返り値が扱いづらい?ということありませんでしたか?
第一引数に渡せるのは関数だけではありません。callableなオブジェクトならなんでも大丈夫です。callableなオブジェクトとは「かっこ()」で呼び出せるものです。
listの各要素に対して一定の処理を行ったモノを使いたい場合にmap関数を使います。戻り値はmapオブジェクトというもので、一種のイテレータです。イテレータとは、for文で回すことができるオブジェクトのことです。mapオブジェクトはlistではありません。 まずは、これをおさえておくとよいでしょう。
実は、第二引数はlistである必要はなく、iterableなものであればOKです。
つまり、次のような書式で使うことができます。
map(callable, *iterable)でも、次のように考えていてもそんなに問題ありません。通常の利用では、これで十分でしょう。
map(function, list)map関数の出力をリスト関数の引数に渡すことでリスト化できます。 次の形ですね。
list(map(関数, 配列オブジェクト))今回は先に書式を整理しました。では、実例でみていきましょう。
サンプルデータ
# サンプルデータの作成
df_sample=pd.DataFrame({
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ'],
'年齢':[23,32,33,21,42,18,15]
})
df_sample
map()
では上記のサンプルーデータに対して、「翌年の年齢」を算出してみましょう。
map(lambda x:x+1,df_sample['年齢'])この実行結果をみると、次のようにmapオブジェクトとなっています。
これの中身を見るには、次のようにlist型に変換するとよいです。
list(map(lambda x:x+1,df_sample['年齢']))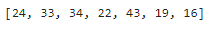
リストの場合はmap(関数, リスト)という関数形式でコードを書きますが、pandasのSeriesに対しては、Series.map(関数)というメソッド形式でコードを書きます。 データフレームに新しい列「翌年の年齢」を追加するのであれば、次のように書く方が自然でしょう。
df_sample['翌年の年齢']=df_sample['年齢'].map(lambda x:x+1)
df_sample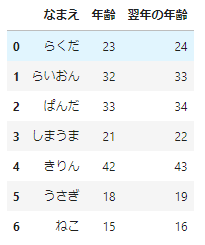
辞書を使った変換
applyでもmapと同様のことができるのですが、この「辞書を使った変換」は、mapメソッドだけです。まずはサンプルデータを作りましょう。
# サンプルデータの作成
df_sample=pd.DataFrame({
'なまえ':['らくだ','らいおん','ぱんだ','しまうま','きりん','うさぎ','ねこ'],
'動物園':['上野動物園','旭山動物園','上野動物園','こどもどうぶつえん','ズーラシア','ズーラシア','旭山動物園'],
'年齢':[23,32,33,21,42,18,15]
})
df_sample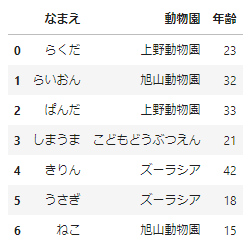
「動物園」の部分を辞書を使って変換することにしましょう。上野動物園は001、旭山動物園は002、こどもどうぶつえんは003、ズーラシアは004とします。
# 辞書の作成
zoo_list={
'上野動物園':'001',
'旭山動物園':'002',
'こどもどうぶつえん':'003',
'ズーラシア':'004'
}
# 辞書を使った変換
df_sample['動物園']=df_sample['動物園'].map(zoo_list)
df_sample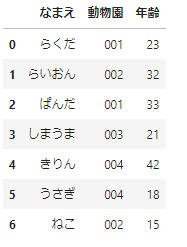
まとめ
いかがでしょうか?データフレームに関数の適用をしたり、値の変換をするのはよく行う作業なので、是非身につけておきたいですね。
コメント